
 Une brève histoire de la gestion des données
Une brève histoire de la gestion des données Edgar F. Codd, informaticien anglo-américain qui a contribué à la théorie et à la pratique des systèmes de gestion de bases de données
Edgar F. Codd, informaticien anglo-américain qui a contribué à la théorie et à la pratique des systèmes de gestion de bases de données 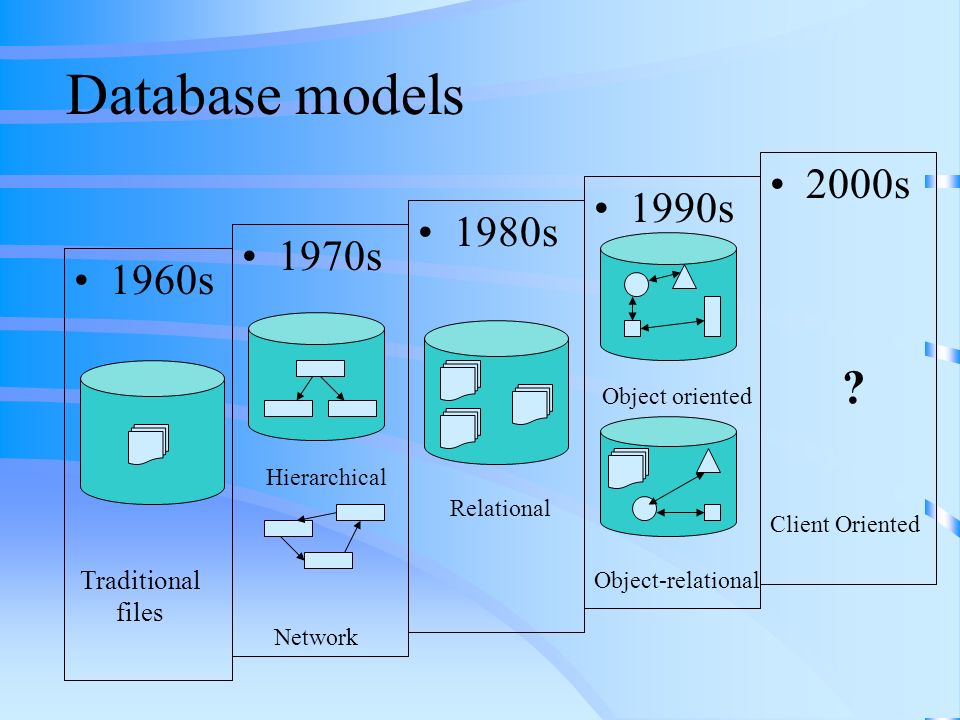 Edgar Frank Codd (1923-2003)
Edgar Frank Codd (1923-2003) Maintenant, presque tout le monde dans la communauté des bases de données sait que le Dr EF Codd est décédé le 18 avril 2003, à l’âge de 79 ans. Le Dr Codd, connu universellement sous le nom de Ted par ses collègues et amis, parmi lesquels je suis fier de compter moi-même – à moi seul, j’ai mis le domaine de la gestion de bases de données sur une base scientifique solide.
Maintenant, presque tout le monde dans la communauté des bases de données sait que le Dr EF Codd est décédé le 18 avril 2003, à l’âge de 79 ans. Le Dr Codd, connu universellement sous le nom de Ted par ses collègues et amis, parmi lesquels je suis fier de compter moi-même – à moi seul, j’ai mis le domaine de la gestion de bases de données sur une base scientifique solide. Toute l’industrie des bases de données relationnelles, qui vaut maintenant plusieurs milliards de dollars par an, doit son existence au travail original de Ted ; il en va de même pour tous les programmes de recherche et d’enseignement sur les bases de données relationnelles dans les universités et les organisations similaires du monde entier. En effet, nous tous qui travaillons dans ce domaine devons nos carrières et nos moyens de subsistance aux contributions de Ted de la fin des années 1960 au début des années 1980. Cet hommage à Ted et à ses réalisations est offert en reconnaissance de la grande dette que nous lui devons tous.
Toute l’industrie des bases de données relationnelles, qui vaut maintenant plusieurs milliards de dollars par an, doit son existence au travail original de Ted ; il en va de même pour tous les programmes de recherche et d’enseignement sur les bases de données relationnelles dans les universités et les organisations similaires du monde entier. En effet, nous tous qui travaillons dans ce domaine devons nos carrières et nos moyens de subsistance aux contributions de Ted de la fin des années 1960 au début des années 1980. Cet hommage à Ted et à ses réalisations est offert en reconnaissance de la grande dette que nous lui devons tous. Ted a commencé sa carrière informatique en 1949 en tant que mathématicien programmeur pour IBM travaillant sur la calculatrice électronique à séquence sélective. Il a ensuite participé au développement de plusieurs produits IBM importants, notamment le 701 (le premier ordinateur électronique commercial d’IBM) et STRETCH, qui a conduit à la technologie mainframe 7090 d’IBM. Puis, à la fin des années 1960, il s’est tourné vers le problème de la gestion des bases de données et, au cours des années suivantes, il a créé le modèle relationnel des données, auquel son nom sera à jamais associé.
Ted a commencé sa carrière informatique en 1949 en tant que mathématicien programmeur pour IBM travaillant sur la calculatrice électronique à séquence sélective. Il a ensuite participé au développement de plusieurs produits IBM importants, notamment le 701 (le premier ordinateur électronique commercial d’IBM) et STRETCH, qui a conduit à la technologie mainframe 7090 d’IBM. Puis, à la fin des années 1960, il s’est tourné vers le problème de la gestion des bases de données et, au cours des années suivantes, il a créé le modèle relationnel des données, auquel son nom sera à jamais associé. Le modèle relationnel est largement reconnu comme l’une des grandes innovations techniques du XXe siècle. Ted l’a décrit et a exploré ses implications dans une série d’articles de recherche incroyablement originaux publiés entre 1969 et 1981. L’effet de ces articles a été double : premièrement, ils ont changé pour de bon la façon dont le monde informatique percevait le problème de gestion des bases de données ; deuxièmement, ils ont jeté les bases d’une toute nouvelle industrie. En fait, ils ont fourni la base d’une technologie qui a eu, et continue d’avoir, un impact majeur sur le tissu même de notre société. Il n’est pas exagéré de dire que Ted est le père intellectuel du domaine des bases de données modernes.
Le modèle relationnel est largement reconnu comme l’une des grandes innovations techniques du XXe siècle. Ted l’a décrit et a exploré ses implications dans une série d’articles de recherche incroyablement originaux publiés entre 1969 et 1981. L’effet de ces articles a été double : premièrement, ils ont changé pour de bon la façon dont le monde informatique percevait le problème de gestion des bases de données ; deuxièmement, ils ont jeté les bases d’une toute nouvelle industrie. En fait, ils ont fourni la base d’une technologie qui a eu, et continue d’avoir, un impact majeur sur le tissu même de notre société. Il n’est pas exagéré de dire que Ted est le père intellectuel du domaine des bases de données modernes. Pour donner une idée de l’étendue des réalisations de Ted, je passerai brièvement en revue certaines de ses contributions les plus importantes. Le plus important de tous était, bien sûr, de faire de la gestion de bases de données une science (introduisant ainsi de la clarté et de la rigueur dans le domaine). Le modèle relationnel a fourni un cadre théorique dans lequel une variété de problèmes importants pouvaient être abordés scientifiquement. Ted a d’abord décrit son modèle dans un rapport de recherche IBM (RJ599) publié le 19 août 1969, Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks. L’année suivante, il a publié une version révisée de cet article, « A Relational Model of Data for Large Shared Data Banks » (Communications of the ACM 13(6): 377–387), qui est généralement crédité d’être l’article fondateur dans le champ.
Pour donner une idée de l’étendue des réalisations de Ted, je passerai brièvement en revue certaines de ses contributions les plus importantes. Le plus important de tous était, bien sûr, de faire de la gestion de bases de données une science (introduisant ainsi de la clarté et de la rigueur dans le domaine). Le modèle relationnel a fourni un cadre théorique dans lequel une variété de problèmes importants pouvaient être abordés scientifiquement. Ted a d’abord décrit son modèle dans un rapport de recherche IBM (RJ599) publié le 19 août 1969, Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks. L’année suivante, il a publié une version révisée de cet article, « A Relational Model of Data for Large Shared Data Banks » (Communications of the ACM 13(6): 377–387), qui est généralement crédité d’être l’article fondateur dans le champ. La plupart des idées nouvelles décrites dans les grandes lignes dans les paragraphes suivants, ainsi que de nombreux développements techniques ultérieurs, ont été annoncés dans ces deux premiers articles; certaines de ces idées n’ont pas encore été complètement explorées. À mon avis, toute personne impliquée professionnellement dans la gestion de bases de données devrait lire et relire au moins un de ces articles chaque année.
La plupart des idées nouvelles décrites dans les grandes lignes dans les paragraphes suivants, ainsi que de nombreux développements techniques ultérieurs, ont été annoncés dans ces deux premiers articles; certaines de ces idées n’ont pas encore été complètement explorées. À mon avis, toute personne impliquée professionnellement dans la gestion de bases de données devrait lire et relire au moins un de ces articles chaque année.
Incidemment, il n’est pas aussi largement connu que Ted n’a pas seulement inventé le modèle relationnel en particulier, il a inventé tout le concept d’un modèle de données en général (cf., « Modèles de données dans la gestion de bases de données », ACM SIGMOD Record 11, No. 2 (février 1981)). Tant pour le modèle relationnel que pour les modèles de données en général, il a souligné l’importance de la distinction entre un modèle de données et son implémentation physique.


Ted a défini la notion clé d’essentialité dans « Interactive Support for Nonprogrammers: The Relational and Network Approaches », Actes de l’atelier ACM SIGMOD sur la description, l’accès et le contrôle des données, vol. II, Ann Arbor, Michigan (mai 1974). Cet article était la principale contribution écrite de Ted à « The Great Debate » – le titre officiel était « Data Models: Data-Structure-Set vs. Relational » – un événement spécial à l’atelier SIGMOD de 1974 caractérisé par la suite par Robert L. Ashenhurst comme « un événement marquant du genre trop rarement observé dans notre domaine. Le concept d’essentialité introduit par Ted dans ce débat est d’une grande aide pour clarifier la pensée dans les discussions sur la nature des systèmes de gestion des données et des bases de données. Le principe d’information (que j’ai entendu Ted qualifier une fois de principe fondamental sous-jacent au modèle relationnel) s’appuie sur lui, bien que de manière peu explicite : » L’ensemble du contenu informatif d’une base de données relationnelle est représenté d’une seule et unique manière : à savoir, en tant que valeurs d’attribut dans des tuples dans des relations.
Le concept d’essentialité introduit par Ted dans ce débat est d’une grande aide pour clarifier la pensée dans les discussions sur la nature des systèmes de gestion des données et des bases de données. Le principe d’information (que j’ai entendu Ted qualifier une fois de principe fondamental sous-jacent au modèle relationnel) s’appuie sur lui, bien que de manière peu explicite : » L’ensemble du contenu informatif d’une base de données relationnelle est représenté d’une seule et unique manière : à savoir, en tant que valeurs d’attribut dans des tuples dans des relations. En plus de toutes ses activités de recherche, Ted était actif professionnellement dans d’autres domaines. Il a fondé le Comité d’intérêt spécial ACM sur la description et la traduction des fichiers (SICFIDET), qui est devenu plus tard un groupe d’intérêt spécial ACM (SIGFIDET) et a changé son nom en Groupe d’intérêt spécial sur la gestion des données (SIGMOD). Il a également été infatigable dans ses efforts, tant à l’intérieur qu’à l’extérieur d’IBM, pour faire accepter le modèle relationnel.
En plus de toutes ses activités de recherche, Ted était actif professionnellement dans d’autres domaines. Il a fondé le Comité d’intérêt spécial ACM sur la description et la traduction des fichiers (SICFIDET), qui est devenu plus tard un groupe d’intérêt spécial ACM (SIGFIDET) et a changé son nom en Groupe d’intérêt spécial sur la gestion des données (SIGMOD). Il a également été infatigable dans ses efforts, tant à l’intérieur qu’à l’extérieur d’IBM, pour faire accepter le modèle relationnel.
 La profondeur et l’étendue des contributions de Ted se reflètent dans la longue liste d’honneurs qui lui ont été conférés au cours de sa vie. Il était boursier IBM, ACM et membre de la British Computer Society. Il a également été membre élu de la National Academy of Engineering et de l’American Academy of Arts and Sciences. Et, en 1981, il a reçu le prix ACM Turing, le prix le plus prestigieux dans le domaine de l’informatique. Il a également reçu de nombreux autres prix professionnels.
La profondeur et l’étendue des contributions de Ted se reflètent dans la longue liste d’honneurs qui lui ont été conférés au cours de sa vie. Il était boursier IBM, ACM et membre de la British Computer Society. Il a également été membre élu de la National Academy of Engineering et de l’American Academy of Arts and Sciences. Et, en 1981, il a reçu le prix ACM Turing, le prix le plus prestigieux dans le domaine de l’informatique. Il a également reçu de nombreux autres prix professionnels.

Ted Codd était un véritable pionnier et une source d’inspiration pour tous ceux qui ont eu la chance et l’honneur de le connaître et de travailler avec lui. Il a toujours été scrupuleux pour créditer les contributions des autres et, malgré ses énormes réalisations, il a pris soin de ne jamais faire de déclarations extravagantes. Par exemple, il ne prétendrait jamais que le modèle relationnel pourrait résoudre tous les problèmes possibles ou qu’il durerait éternellement. Pourtant, ceux qui comprennent vraiment ce modèle croient que la classe de problèmes qu’il peut résoudre est extraordinairement large et qu’il durera très longtemps. Les systèmes seront construits sur la base du modèle relationnel de Codd à la portée de tous. Originaire d’Angleterre, Ted a servi dans la Royal Air Force pendant la Seconde Guerre mondiale. Il a déménagé aux États-Unis après la guerre et est devenu citoyen américain naturalisé. Il était titulaire d’une maîtrise en mathématiques et en chimie de l’Université d’Oxford, d’une maîtrise et d’un doctorat. en sciences de la communication de l’Université du Michigan. Il laisse dans le deuil sa femme, Sharon; une fille, Katherine; trois fils, Ronald, Frank et David; six petits-enfants; d’autres membres de la famille; et amis et collègues du monde entier. Il est pleuré et manque cruellement à tous.
Originaire d’Angleterre, Ted a servi dans la Royal Air Force pendant la Seconde Guerre mondiale. Il a déménagé aux États-Unis après la guerre et est devenu citoyen américain naturalisé. Il était titulaire d’une maîtrise en mathématiques et en chimie de l’Université d’Oxford, d’une maîtrise et d’un doctorat. en sciences de la communication de l’Université du Michigan. Il laisse dans le deuil sa femme, Sharon; une fille, Katherine; trois fils, Ronald, Frank et David; six petits-enfants; d’autres membres de la famille; et amis et collègues du monde entier. Il est pleuré et manque cruellement à tous.
La vie et les contributions du Dr Edgar F. Codd Le Dr Edgar F. Codd était surtout connu pour avoir créé le modèle « relationnel » de représentation des données qui a conduit à l’industrie des bases de données d’aujourd’hui (« Edgar F. Codd ») (Edgar F. Codd). Il a reçu de nombreux prix pour ses contributions et il est l’une des nombreuses raisons pour lesquelles nous avons certaines des technologies aujourd’hui. En approfondissant sa vie dans ce document de recherche, nous découvrirons que le Dr Edgar F. Codd était en fait un génie motivé.
Le Dr Edgar F. Codd était surtout connu pour avoir créé le modèle « relationnel » de représentation des données qui a conduit à l’industrie des bases de données d’aujourd’hui (« Edgar F. Codd ») (Edgar F. Codd). Il a reçu de nombreux prix pour ses contributions et il est l’une des nombreuses raisons pour lesquelles nous avons certaines des technologies aujourd’hui. En approfondissant sa vie dans ce document de recherche, nous découvrirons que le Dr Edgar F. Codd était en fait un génie motivé.
Le Dr Edgar F. Codd a commencé sa vie monumentale sur la côte sud de l’Angleterre le 19 août 1923 (date). Son éducation a consisté à fréquenter la Poole Grammar School dans le Dorset, au Royaume-Uni et l’Université d’Oxford. Il a reçu une bourse complète à Oxford et a d’abord commencé à étudier la chimie en 1941-1942. Au bout d’un moment, Codd a interrompu ses études pour se porter volontaire pour le service actif même si on lui a proposé un sursis. Il accède au poste de lieutenant du Royal Air Force Coastal Command jusqu’à la fin de la guerre. Après la fin de la guerre, il reprend ses études à Oxford, changeant sa majeure en mathématiques. Il a finalement obtenu son diplôme de mathématiques en 1948.
 Évidemment pour subvenir à ses besoins, il s’est lancé en affaires avec des collègues (date). Ils ont créé deux sociétés – The Relational Institute et Codd & Date Consulting Group. Ces sociétés se sont spécialisées dans tous les aspects de la gestion, de la conception et de l’évaluation de bases de données relationnelles . Codd a pu voir l’industrie des bases de données se développer et s’élever à des dizaines de milliards de dollars par an.
Évidemment pour subvenir à ses besoins, il s’est lancé en affaires avec des collègues (date). Ils ont créé deux sociétés – The Relational Institute et Codd & Date Consulting Group. Ces sociétés se sont spécialisées dans tous les aspects de la gestion, de la conception et de l’évaluation de bases de données relationnelles . Codd a pu voir l’industrie des bases de données se développer et s’élever à des dizaines de milliards de dollars par an.
Alors que Codd approchait de la fin de sa vie, il étudiait la possibilité d’appliquer ses idées au problème de l’automatisation commerciale générale (Date). Finalement, la vie de Codd a pris fin le 18 avril 2003. Il est décédé dans sa maison de Williams Island, en Floride (Hafner). À la suite de sa vie d’enquête, le Dr Edgar. F Codd s’est mérité sa place parmi les personnes distinguées qui ont influencé la technologie d’aujourd’hui. Dr Edgar F. Codd Le Dr Edgar F. Codd était surtout connu pour avoir créé le modèle « relationnel » de représentation des données qui a conduit à l’industrie des bases de données d’aujourd’hui (« Edgar F. Codd ») (Edgar F. Codd). Il a reçu de nombreux prix pour ses contributions et il est l’une des nombreuses raisons pour lesquelles nous avons certaines des technologies aujourd’hui. En approfondissant sa vie dans ce document de recherche, nous découvrirons que le Dr Edgar F. Codd était en fait un génie motivé. Le Dr Edgar F. Codd a commencé sa vie monumentale sur la côte sud de l’Angleterre le 19 août 1923 (date). Son éducation a consisté à fréquenter la Poole Grammar School dans le Dorset, au Royaume-Uni et l’Université d’Oxford. Il a reçu une bourse complète à Oxford et a d’abord commencé à étudier la chimie.
Dr Edgar F. Codd Le Dr Edgar F. Codd était surtout connu pour avoir créé le modèle « relationnel » de représentation des données qui a conduit à l’industrie des bases de données d’aujourd’hui (« Edgar F. Codd ») (Edgar F. Codd). Il a reçu de nombreux prix pour ses contributions et il est l’une des nombreuses raisons pour lesquelles nous avons certaines des technologies aujourd’hui. En approfondissant sa vie dans ce document de recherche, nous découvrirons que le Dr Edgar F. Codd était en fait un génie motivé. Le Dr Edgar F. Codd a commencé sa vie monumentale sur la côte sud de l’Angleterre le 19 août 1923 (date). Son éducation a consisté à fréquenter la Poole Grammar School dans le Dorset, au Royaume-Uni et l’Université d’Oxford. Il a reçu une bourse complète à Oxford et a d’abord commencé à étudier la chimie.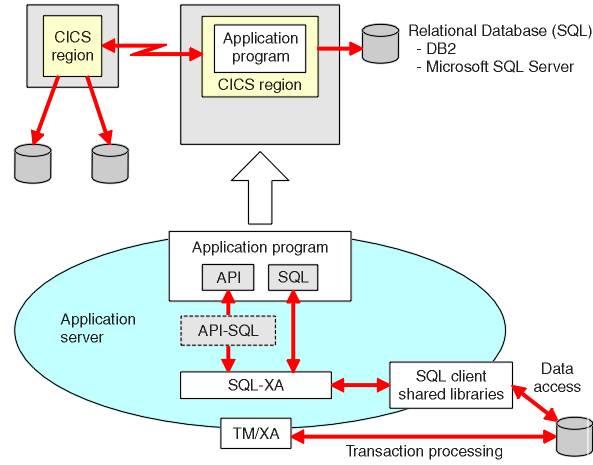 Bénéficiant grandement de l’efficacité des ordinateurs, le SSEC a ouvert la voie vers la gamme d’ordinateurs que nous utilisons aujourd’hui. Codd a continué à recevoir une formation continue concernant sa profession (date). Il a reçu une bourse d’IBM pour fréquenter l’Université du Michigan, et il a obtenu son M.Sc. et doctorat. en sciences de la communication. Il est retourné à Poughkeepsie IBM peu de temps après avoir obtenu son diplôme, où il a travaillé sur des techniques de haut niveau pour la spécification logicielle. À peu près à cette époque, il a commencé à aller dans la direction pour laquelle il est maintenant bien connu. Il a tourné son attention vers la base de données questions. De nombreux produits de base de données étaient disponibles à l’époque, mais ils étaient particulièrement difficiles à utiliser. De plus, ces produits ne pouvaient être utilisés que par des personnes possédant des compétences techniques hautement spécialisées. Un autre inconvénient était qu’il n’y avait pas de base théorique solide quant à la façon dont ces systèmes fonctionnaient. Codd tourna intensément son attention vers ce problème et était déterminé à trouver une solution. C’est là que son éducation mathématique l’a beaucoup aidé. Il a pu fournir une base en créant le « modèle relationnel des données » (« Date »). À la suite de ses idées, cette théorie et fondement du « mode relationnel des données » est l’une des grandes réalisations techniques les plus largement reconnues du XXe siècle (« Edgar F. Codd ») (Date).
Bénéficiant grandement de l’efficacité des ordinateurs, le SSEC a ouvert la voie vers la gamme d’ordinateurs que nous utilisons aujourd’hui. Codd a continué à recevoir une formation continue concernant sa profession (date). Il a reçu une bourse d’IBM pour fréquenter l’Université du Michigan, et il a obtenu son M.Sc. et doctorat. en sciences de la communication. Il est retourné à Poughkeepsie IBM peu de temps après avoir obtenu son diplôme, où il a travaillé sur des techniques de haut niveau pour la spécification logicielle. À peu près à cette époque, il a commencé à aller dans la direction pour laquelle il est maintenant bien connu. Il a tourné son attention vers la base de données questions. De nombreux produits de base de données étaient disponibles à l’époque, mais ils étaient particulièrement difficiles à utiliser. De plus, ces produits ne pouvaient être utilisés que par des personnes possédant des compétences techniques hautement spécialisées. Un autre inconvénient était qu’il n’y avait pas de base théorique solide quant à la façon dont ces systèmes fonctionnaient. Codd tourna intensément son attention vers ce problème et était déterminé à trouver une solution. C’est là que son éducation mathématique l’a beaucoup aidé. Il a pu fournir une base en créant le « modèle relationnel des données » (« Date »). À la suite de ses idées, cette théorie et fondement du « mode relationnel des données » est l’une des grandes réalisations techniques les plus largement reconnues du XXe siècle (« Edgar F. Codd ») (Date). Une brève histoire de la gestion des données
Une brève histoire de la gestion des données
La gestion des données est l’organisation des données, les étapes utilisées pour atteindre l’efficacité et recueillir des renseignements commerciaux à partir de ces données.Gestion de données, en tant que concept, a commencé dans les années 1960, avec ADAPSO (l’Association des organisations de services de traitement de données) transmettant des conseils en gestion des données, en mettant l’accent sur la formation professionnelle et les mesures d’assurance qualité. La gestion des données a considérablement évolué au cours des six dernières décennies.
La gestion des données ne doit pas être confondue avec Gouvernance des données, ni avec Gestion de base de données. La gouvernance des données est un ensemble de pratiques et de concepts qui hiérarchisent et organisent les données, ainsi que l’application de politiques autour des données, tout en suivant diverses réglementations et en limitant les mauvaises pratiques en matière de données. Gouvernance des donnéesest essentiellement une partie du plus grand ensemble de la gestion des données. La gestion de base de données, quant à elle, se concentre sur les outils et la technologie utilisés pour créer et modifier la base des données, plutôt que sur le système global utilisé pour organiser les données. La gestion de la base de données est également une subdivision de la gestion des données.
Gouvernance des donnéesest essentiellement une partie du plus grand ensemble de la gestion des données. La gestion de base de données, quant à elle, se concentre sur les outils et la technologie utilisés pour créer et modifier la base des données, plutôt que sur le système global utilisé pour organiser les données. La gestion de la base de données est également une subdivision de la gestion des données.
Pour mieux comprendre la gestion des données, considérez ce qui suit : Chaque aéroport a des vols au départ. Chaque passager a une destination et atteindre chaque destination nécessite un ou plusieurs vols. De plus, chaque vol a un certain nombre de passagers.  Les informations pourraient être affichées de manière hiérarchique, mais cette méthode présente un problème majeur. Les données affichées peuvent être centrées sur les vols, les passagers ou les destinations, mais pas les trois simultanément. L’affichage de trois hiérarchies distinctes nécessite de stocker les données de manière redondante et commence à devenir coûteux. De plus, mettre à jour les données dans trois fichiers distincts est plus difficile que de les mettre à jour dans un seul. Les trois hiérarchies doivent être mises à jour pour éliminer toute confusion. Utilisant un modèle de données réseau, qui est beaucoup plus flexible, offre une meilleure solution. Une bonne gestion des données est la clé d’une entreprise prospère.
Les informations pourraient être affichées de manière hiérarchique, mais cette méthode présente un problème majeur. Les données affichées peuvent être centrées sur les vols, les passagers ou les destinations, mais pas les trois simultanément. L’affichage de trois hiérarchies distinctes nécessite de stocker les données de manière redondante et commence à devenir coûteux. De plus, mettre à jour les données dans trois fichiers distincts est plus difficile que de les mettre à jour dans un seul. Les trois hiérarchies doivent être mises à jour pour éliminer toute confusion. Utilisant un modèle de données réseau, qui est beaucoup plus flexible, offre une meilleure solution. Une bonne gestion des données est la clé d’une entreprise prospère. La gestion des données est devenue un problème pour la première fois dans les années 1950, lorsque les ordinateurs étaient lents, maladroits et nécessitaient d’énormes quantités de travail manuel pour fonctionner. Plusieurs entreprises axées sur l’informatique utilisaient des étages entiers pour stocker et « gérer » uniquement les cartes perforées stockant leurs données. Ces mêmes entreprises utilisaient d’autres étages pour entretenir des trieuses, des tabulatrices et des banques de cartes perforées. Les programmes de l’époque étaient configurés sous une forme binaire ou décimale et étaient lus à partir d’interrupteurs marche / arrêt à l’avant de l’ordinateur, ou d’une bande magnétique ou même de cartes perforées. Cette forme de programmation s’appelait à l’origine Absolute Machine Language (et a ensuite été changée en Langages de programmation de première génération).
La gestion des données est devenue un problème pour la première fois dans les années 1950, lorsque les ordinateurs étaient lents, maladroits et nécessitaient d’énormes quantités de travail manuel pour fonctionner. Plusieurs entreprises axées sur l’informatique utilisaient des étages entiers pour stocker et « gérer » uniquement les cartes perforées stockant leurs données. Ces mêmes entreprises utilisaient d’autres étages pour entretenir des trieuses, des tabulatrices et des banques de cartes perforées. Les programmes de l’époque étaient configurés sous une forme binaire ou décimale et étaient lus à partir d’interrupteurs marche / arrêt à l’avant de l’ordinateur, ou d’une bande magnétique ou même de cartes perforées. Cette forme de programmation s’appelait à l’origine Absolute Machine Language (et a ensuite été changée en Langages de programmation de première génération). Langages de programmation de deuxième génération
Langages de programmation de deuxième génération
Langages de programmation de deuxième génération (anciennement appelés Langages d’assemblage) ont été utilisés comme une des premières méthodes d’organisation et de gestion des données. Ces langages sont devenus populaires à la fin des années 1950 et utilisaient des lettres de l’alphabet pour la programmation, plutôt qu’une chaîne complexe de uns et de zéros. Pour cette raison, les programmeurs peuvent utiliser des mnémoniques d’assemblage, ce qui facilite la mémorisation des codes. Ces langages sont maintenant désuets, mais ont contribué à rendre les programmes beaucoup plus lisibles pour les humains et ont libéré les programmeurs des calculs fastidieux et sujets aux erreurs.
Langages de haut niveau
Une compréhension des langages fondamentaux peut aider à créer un nouveau service ou une nouvelle application Web.
Les langages de haut niveau (HLL) sont des langages de programmation plus anciens qui étaient faciles à lire par les humains. Certains sont encore populaires. Certains ne le sont pas. Ils permettent à un programmeur d’écrire des programmes génériques qui ne dépendent pas complètement d’un type spécifique d’ordinateur. Bien que ces langages mettent l’accent sur la facilité d’utilisation, leur objectif principal est d’organiser et de gérer les données. Différents langages de haut niveau présentent des atouts différents :
- Fortran a été créé à l’origine par IBM dans les années 1950 pour les applications d’ingénierie et de science. Il est toujours utilisé pour la prévision numérique du temps, l’analyse par éléments finis, la dynamique des fluides computationnelle, la physique computationnelle, la cristallographie et la chimie computationnelle.
- Zézayer (historiquement, LISP) a été décrit à l’origine en 1958 et est rapidement devenu un langage de programmation préféré pour la recherche en IA. Il était inhabituel en ce qu’il ne faisait aucune distinction entre les données et le code, et était l’un des premiers langages de programmation à initier un certain nombre d’idées en informatique, telles que la gestion automatique du stockage, le typage dynamique et les structures de données arborescentes. Lisp avait également la possibilité de se développer d’une manière à laquelle ses concepteurs n’avaient jamais pensé. (Lisp est en déclin.)
- COBOL (Common Business Oriented Language) a été développé par CODASYL en 1959 et faisait partie d’un objectif du Département américain de la Défense de créer un langage de programmation « portable » pour le traitement des données. Il s’agit d’un langage de programmation de type anglais conçu principalement pour les systèmes commerciaux, financiers et administratifs. En 2002,COBOL a été révisé et est devenu un langage de programmation orienté objet.
- BASIQUE (le Beginner’s All-purpose Symbolic Instruction Code) décrit un groupe de langages de programmation à usage général conçus pour être conviviaux. Il a été conçu en 1964 au Dartmouth College. (Le BASIC n’est pas beaucoup utilisé de nos jours.)
- C a été inventé aux Bell Labs dans les années 1970 et avait un système d’exploitation écrit à l’intérieur. Le système d’exploitation était UNIX, et comme le programme était écrit en C, UNIX pouvait désormais être transporté vers un autre système. (À l’heure actuelle, il continue d’être l’un des langages de programmation les plus populaires au monde.)
- C++ (prononcé « c plus plus ») est basé sur C et est un langage de programmation à usage général, avec une manipulation de la mémoire de bas niveau. Il a été conçu pour être facilement modifié, est livré avec des applications de bureau et peut être installé sur diverses plates-formes. (Il est encore largement utilisé et sa popularité semble croître.)
 Extraire, transformer et chargerL’un des premiers Outils de gestion des données est l’ETL. ETL (extraire, transformer et charger) a commencé à gagner en popularité dans les années 1970 et reste l’une des techniques d’intégration de données les plus populaires sur le marché. Il collecte des données provenant de différentes sources et les convertit en une forme cohérente. Les données intégrées sont ensuite téléchargées dans un entrepôt de données (ou un autre système de stockage).
Extraire, transformer et chargerL’un des premiers Outils de gestion des données est l’ETL. ETL (extraire, transformer et charger) a commencé à gagner en popularité dans les années 1970 et reste l’une des techniques d’intégration de données les plus populaires sur le marché. Il collecte des données provenant de différentes sources et les convertit en une forme cohérente. Les données intégrées sont ensuite téléchargées dans un entrepôt de données (ou un autre système de stockage).
La gestion de base de données en tant que composante de la gestion des données
La gestion des données a constamment évolué pour inclure un large éventail de technologies et d’outils. Cela inclut le logiciel de gestion de base de données en tant que composant du système de gestion des données. Les systèmes de gestion de base de données sont la forme la plus courante de plates-formes de gestion de données et agissent comme une interface entre la base de données et l’utilisateur final.
Deux systèmes de gestion de base de données populaires sont SQL, un système de gestion de base de données relationnelle (RDBMS) et NoSQL, une base de données qui stocke des données à l’aide de formats de stockage non relationnels, et qui sont souvent évolutives (ou extensibles).
Gestion des données en ligne systèmes, tels que les réservations de voyages et les transactions boursières, doivent coordonner et gérer les données rapidement et efficacement. À la fin des années 1950, plusieurs industries ont commencé à expérimenter les transactions en ligne. Actuellement, les systèmes de gestion des données en ligne peuvent traiter des informations sur les soins de santé (pensez efficacité) ou mesurer, stocker et analyser jusqu’à 7,5 millions de sessions de soudage par jour (pensez productivité). Ces systèmes permettent à un programme de lire des fichiers ou des enregistrements, de les mettre à jour et de renvoyer les informations mises à jour à l’utilisateur en ligne.
SQL
SQL (langage de requête structuré) a été développé par Edgar F. Codd dans les années 1970 et s’est concentré sur les bases de données relationnelles, fournissant un traitement de données cohérent et réduisant la quantité de données dupliquées. Le programme est également assez facile à apprendre, car il répond aux commandes en anglais (par opposition à un langage informatique). Le modèle relationnel permet de traiter rapidement et efficacement de grandes quantités de données. La langue s’est normalisée en 1985.
Les modèles relationnels représentent à la fois les relations et le sujet de manière uniforme. Une caractéristique de modèles de données relationnellesest leur utilisation d’un langage unifié lors de la navigation, de la manipulation et de la définition des données, plutôt que d’utiliser des langages distincts pour chaque tâche. L' »algèbre » relationnelle est utilisée pour traiter les ensembles d’enregistrements en tant que groupe, les « opérateurs » étant appliqués à des ensembles d’enregistrements entiers. Les modèles de données relationnels, combinés aux opérateurs, fournissent des programmes plus courts et plus simples.

Le modèle relationnel a présenté des avantages inattendus. Il s’est avéré très bien adapté au traitement parallèle, à l’informatique client-serveur et aux GUI (interfaces utilisateur graphiques). De plus, un système de modèle de base de données relationnelle (RDBMS) permet à plusieurs utilisateurs d’accéder simultanément à la même base de données. NoSQL
NoSQL

Le primaire but de NoSQLest le traitement et la recherche de Big Data. Il a commencé comme un moteur de recherche, avec quelques fonctionnalités de gestion supplémentaires, et ne fait « pas » partie d’une base de données relationnelle. Cela a changé maintenant avec des plates-formes NoSQL beaucoup plus avancées. Bien que des données structurées puissent être utilisées pendant la recherche, ce n’est pas nécessaire. La véritable force de NoSQL est sa capacité à stocker et à filtrer d’énormes quantités de données structurées et non structurées. Le Manager de donnéesa un variété de bases de données NoSQLà choisir, chacun avec ses propres atouts spécifiques. Les bases de données NoSQL sont couramment utilisées pour la recherche sur le Big Data, car elles peuvent stocker et gérer une variété de types de données.
L’efficacité de NoSQL est le résultat de sa nature non structurée, échangeant la cohérence contre la vitesse et l’agilité. Ce style d’architecture prend en charge l’évolutivité horizontale et a permis des entrepôts de données(Amazon, Google et la CIA) pour traiter de grandes quantités d’informations. NoSQL est excellent pour traiter le Big Data. Le terme « big data » a commencé à s’estomper depuis 2019-20, car l’utilisation de quantités massives de données est désormais la norme.
Le concept de NoSQL est né en 1998 et a été utilisé pour la première fois par Carlo Strozzi, mais n’a commencé à gagner en popularité qu’après 2005, lorsque Doug Cutting et Mike Cafarella ont publié Nutch pour le grand public. Nutch a conduit à Hadoop (maintenant appelé Apache Hadoop), et en tant que logiciel open source « gratuit », est rapidement devenu très populaire. Intégration de données
Intégration de données
Intégration de données peut être décrit comme la combinaison de données recueillies auprès de plusieurs sources et la transformation de ces données afin qu’elles puissent être présentées de manière unifiée. Le premier système d’intégration de données a été conçu en 1991 pour l’Université du Minnesota. L’objectif initial était de faciliter l’utilisation et le traitement des données, tant pour les systèmes que pour les personnes.
Le pipeline de données
EN 1999, les pipelines de données commençaient à être utilisés à l’appui d’Internet. Un pipeline de données est une forme d’architecture informatique conçue pour collecter, organiser et acheminer les données à utiliser davantage dans l’analyse des données. Les ETL (ou un équivalent) font partie de l’architecture du pipeline de données. D’une manière générale, un pipeline de données est une série automatisée d’étapes effectuées sur les données. Il est souvent utilisé pour collecter et traiter des données provenant de plusieurs sources, puis les envoyer à un entrepôt de données, ou pour les utiliser pour une forme d’analyse.
Catalogues de données
Au début des années 2000, les catalogues de données ont commencé à être utilisés pour la gestion des données, la gestion des métadonnées et la conservation des données. Essentiellement, un catalogue de données enregistre les actifs de données disponibles d’une organisation et les organise. Le catalogage des données comprend des tâches telles que l’ingestion de métadonnées, la découverte de métadonnées et la création de relations sémantiques entre les métadonnées.
Centres de données
Au milieu des années 2000, les data hubs sont devenus une forme de Data Management. Ils ont commencé à être utilisés pour stocker des données et agir comme un point d’intégration à l’aide d’une architecture en étoile. Un moderne hub de données utilise une architecture de stockage centrée sur les données pour consolider et partager les données afin de prendre en charge les charges de travail d’analyse et d’IA.
Les hubs de données modernes effectuent le traitement de flux, le traitement par lots et le traitement AI/ML Les fonctionnalités AI/ML permettent d’effectuer un traitement analytique dans le hub, plutôt que de déplacer d’énormes quantités de données sur un réseau pour analyse. Des fonctionnalités telles que l’exploration des données, la protection des données, l’indexation et la gestion des métadonnées sont proposées par les hubs de données modernes.
Mégadonnées et lacs de données
NoSQL, avec sa mémoire extensible et sa capacité à traiter des données structurées et non structurées, a ouvert les portes à la recherche sur le Big Data.Entrepôts de données et lacs sont deux systèmes de stockage de données couramment utilisés pour la recherche de données (analytique).
Les outils de gestion des données pour les entrepôts de données diffèrent de ceux utilisés par les lacs de données, en ce sens que les entrepôts de données sont généralement utilisés avec une base de données relationnelle (SQL) et stockent des données structurées recueillies à partir de diverses sources et préparées pour l’analyse. Les entrepôts de données sont principalement utilisés pour rapports d’entrepriseet limité l’intelligence d’entreprise.
Les lacs de données, quant à eux, stockent une grande masse de données non structurées (NoSQL) pour l’apprentissage automatique, l’informatique décisionnelle à grande échelle et d’autres applications d’analyse. Les lacs de données stockent souvent des données brutes qui ont été stockées telles quelles. Le crédit pour le terme « lacs de données » est attribué à James Dixon, qui l’a utilisé en octobre 2010,
Gouvernance des données
La gouvernance des données fait généralement partie d’une plate-forme de gestion des données, conçue pour garantir la qualité et la convivialité des données collectées par une organisation. Les premières versions de Gouvernance des donnéesles programmes étaient axés sur le catalogage des données.
En 2005, la gouvernance des données a commencé à gagner en popularité en tant que moyen d’accéder à des données de qualité à des fins de recherche de mégadonnées.
L’Union européenne RGPD(Règlement général sur la protection des données) est entré en vigueur en 2016, obligeant de nombreuses entreprises à se démener pour essayer de respecter les nouvelles normes de conformité. La solution informatique la plus simple pour faire face aux nouvelles lois sur la protection de la vie privée consistait à développer de nouveaux Logiciel de gouvernance des données.
En 2018, il y a eu un certain nombre de violations de données massives ciblant une variété d’organisations dans différents secteurs (par exemple Facebook, Equifax, Yahoo et Marriott). En conséquence, la sécurité et la gouvernance des données sont devenues étroitement liées.
Structure de données
Une plateforme de Data Fabric améliore la gestion des données en automatisant les tâches répétitives. La structure de données utilise une combinaison de technologie et d’architecture conçue pour gérer plusieurs types de données à partir de plusieurs systèmes de gestion de bases de données. Il fournit une plate-forme de gestion de données plus sophistiquée.
Structure de données est une plate-forme unique conçue pour gérer toutes sortes de données et différentes technologies à partir de plusieurs centres de données, y compris le cloud.
Cependant, l’objectif principal d’une structure de données est l’orchestration des données, ce qui nécessite une coordination avec l’ingestion, le stockage, la préparation et les pipelines de données. Il comprend également une gestion, une gouvernance et une sécurité améliorées des métadonnées.
Gestion des données dans le cloud
La gestion des données dans le cloud devient rapidement une responsabilité supplémentaire pour les gestionnaires de données internes. Bien que le concept de stockage en nuage ait été développé dans les années 1960, il n’est pas devenu un réalité jusqu’en 1999, lorsque Salesforce proposait la livraison d’applications via son site Web.Amazon a imité l’idée en 2002, fournissant des services basés sur Internet (cloud), qui comprenaient le stockage. L’utilisation louée d’applications et de services sur un site Web, via Internet, est rapidement devenue un moyen populaire de traiter des projets importants et inhabituels. Au fur et à mesure que le confort avec les services se développait, de nombreuses organisations ont commencé à déplacer l’essentiel de leurs activités de stockage et de traitement, au nuage. Par conséquent, un certain nombre de start-ups cloud se sont formées.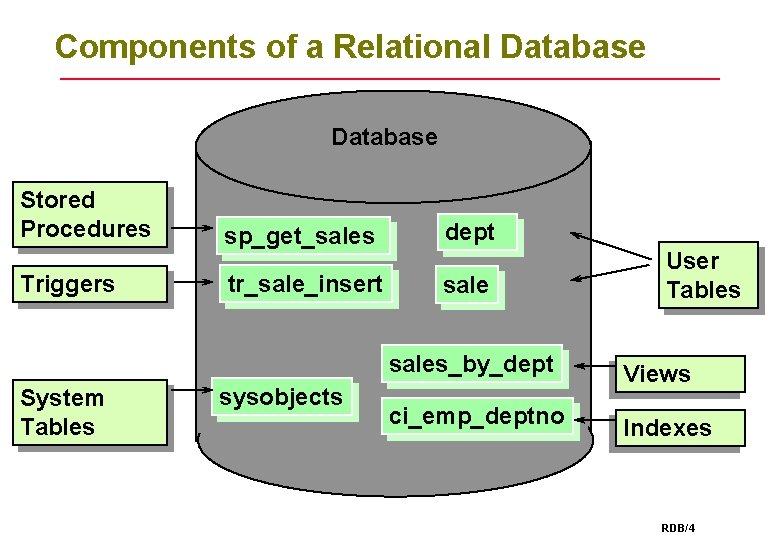 Le cloud fournit désormais aux organisations des ressources dédiées à la gestion des données, selon leurs besoins. Les avantages de la gestion des données dans le nuage incluent :
Le cloud fournit désormais aux organisations des ressources dédiées à la gestion des données, selon leurs besoins. Les avantages de la gestion des données dans le nuage incluent :
- Accès à une technologie de pointe.
- La réduction des coûts de maintenance du système en interne.
- Flexibilité accrue pour répondre aux besoins changeants des entreprises.
- Le traitement des mégadonnées.
Les SLA (Service Level Agreements) sont les contrats utilisés pour convenir de garanties entre les clients et un fournisseur de services. Étant donné que l’architecture des différents fournisseurs de cloud varie, il est dans l’intérêt du gestionnaire de données d’enquêter ets électionner le meilleur ajustement, en fonction des besoins de leur organisation. La compatibilité de la sécurité d’un cloud et l’accès au stockage sont deux préoccupations cruciales pour un gestionnaire de données cloud et doivent faire l’objet de recherches approfondies. Intelligence artificielle et gestion des données
Intelligence artificielle et gestion des données
Il est prévisible que, dans les dix prochaines années, L’IA aidera à organiser et trier d’énormes quantités de données stockées et prendre des décisions de routine sur les procédures de base. Il deviendra de plus en plus précieux en tant qu’assistant du gestionnaire de données. Voici quelques exemples :
- Traiter, gérer et stocker des données non structurées.
- Suppression des données non pertinentes.
- Optimisation de l’intégration des données pour la recherche et les requêtes d’informations.
- Déterminer la valeur des données et le meilleur emplacement pour les stocker.
Intelligence artificielle a un grand potentiel pour aider les gestionnaires de données à développer et à gérer un programme de gestion des données hautement fonctionnel. Histoire du SGBD
Histoire du SGBD
Les données sont un ensemble de faits et de chiffres. La collecte de données augmentait de jour en jour et elles devaient être stockées dans un appareil ou un logiciel plus sûr.
Charles Bachman a été la première personne à développer le magasin de données intégré (IDS) qui était basé sur un modèle de données de réseau pour lequel il a été inauguré avec le prix Turing (le prix le plus prestigieux qui équivaut au prix Nobel dans le domaine de l’informatique.) . Il a été développé au début des années 1960.
À la fin des années 1960, IBM (International Business Machines Corporation) a développé les systèmes de gestion intégrés qui sont le système de base de données standard utilisé jusqu’à ce jour dans de nombreux endroits. Il a été développé sur la base du modèle de base de données hiérarchique. C’est au cours de l’année 1970 que le modèle de base de données relationnelle a été développé par Edgar Codd. De nombreux modèles de bases de données que nous utilisons aujourd’hui sont basés sur des relations. Il était alors considéré comme le modèle de base de données standardisé. Le modèle relationnel était encore utilisé par de nombreuses personnes sur le marché. Plus tard au cours de la même décennie (années 1980), IBM a développé le langage de requête structuré (SQL) dans le cadre du projet R. Il a été déclaré comme langage standard pour les requêtes par ISO et ANSI. Les systèmes de gestion des transactions pour le traitement des transactions ont également été développés par James Gray pour lesquels il a reçu le prix Turing.
Le modèle relationnel était encore utilisé par de nombreuses personnes sur le marché. Plus tard au cours de la même décennie (années 1980), IBM a développé le langage de requête structuré (SQL) dans le cadre du projet R. Il a été déclaré comme langage standard pour les requêtes par ISO et ANSI. Les systèmes de gestion des transactions pour le traitement des transactions ont également été développés par James Gray pour lesquels il a reçu le prix Turing.
En outre, il existait de nombreux autres modèles dotés de fonctionnalités riches telles que des requêtes complexes, des types de données pour insérer des images et bien d’autres. L’ère d’Internet a peut-être beaucoup plus influencé les modèles de données. Les modèles de données ont été développés à l’aide de fonctionnalités de programmation orientées objet, intégrant des langages de script tels que Hyper Text Markup Language (HTML) pour les requêtes. Avec d’énormes données disponibles en ligne, le SGBD gagne en importance de jour en jour.
Edgar Frank Codd (1923-2003) Informaticien et mathématicien anglo-américain qui a jeté les bases théoriques des bases de données relationnelles, pour stocker et récupérer des informations dans des enregistrements informatiques. Il a également apporté des connaissances dans le domaine des automates cellulaires.
Informaticien et mathématicien anglo-américain qui a jeté les bases théoriques des bases de données relationnelles, pour stocker et récupérer des informations dans des enregistrements informatiques. Il a également apporté des connaissances dans le domaine des automates cellulaires.

https://www.123helpme.com/essay/The-Life-and-Contributions-of-Dr-Edgar-360258
https://www.bartleby.com/essay/The-Life-and-Contributions-of-Dr-Edgar-P3DSPUAVJ
https://www.nae.edu/187653/EDGAR-F-CODD-19232003