
 La naissance du Web
La naissance du Web![]() 30 avril 1993 – World Wide Web mis à la disposition du public
30 avril 1993 – World Wide Web mis à la disposition du public Logiciel World-Wide Web au CERN
Logiciel World-Wide Web au CERN Le code source du World Wide Web est publié par le CERN, rendant le logiciel librement accessible à tous
Le code source du World Wide Web est publié par le CERN, rendant le logiciel librement accessible à tous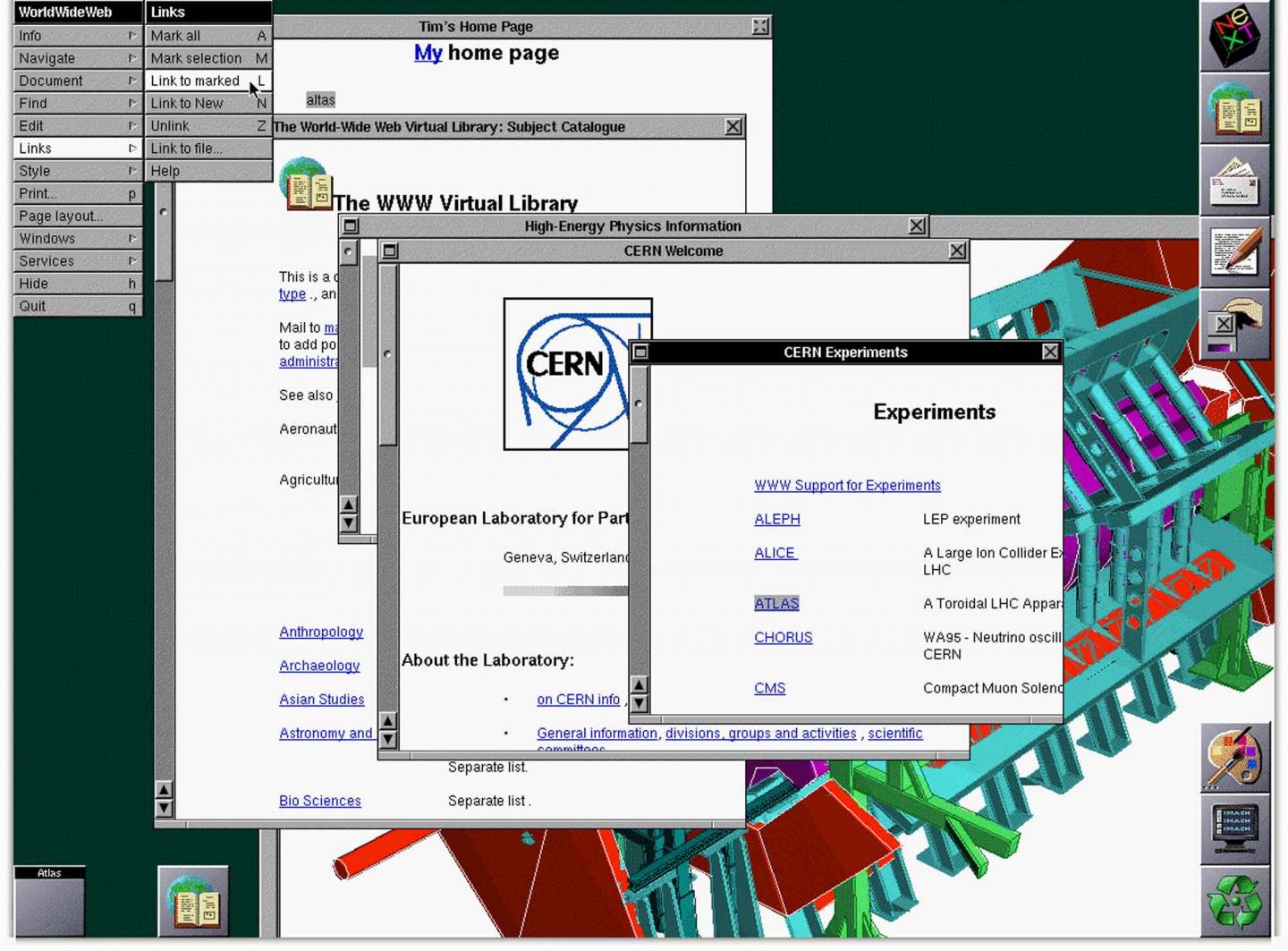 Petite histoire du Web – Où le Web est né
Petite histoire du Web – Où le Web est né:strip_icc()/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2020/l/O/BB24klQCeSXGP1rRkgzA/32bits.png) Tim Berners-Lee, un scientifique britannique, a inventé le World Wide Web (WWW) en 1989, alors qu’il travaillait au CERN.
Tim Berners-Lee, un scientifique britannique, a inventé le World Wide Web (WWW) en 1989, alors qu’il travaillait au CERN.

Le CERN n’est pas un laboratoire isolé, mais plutôt le point focal d’une vaste communauté qui comprend plus de 17 000 scientifiques de plus de 100 pays. Bien qu’ils passent généralement du temps sur le site du CERN, les scientifiques travaillent généralement dans des universités et des laboratoires nationaux dans leur pays d’origine. Des outils de communication fiables sont donc essentiels.
L’idée de base du WWW était de fusionner les technologies évolutives des ordinateurs, des réseaux de données et de l’hypertexte dans un système d’information mondial puissant et facile à utiliser.
Comment le Web a commencé 
À la fin de 1990, Tim Berners-Lee avait le premier serveur et navigateur Web opérationnel au CERN, démontrant ses idées. Il a développé le code de son serveur Web sur un ordinateur NeXT. Pour éviter qu’il ne s’éteigne accidentellement, l’ordinateur avait une étiquette manuscrite à l’encre rouge : « Cette machine est un serveur. NE LA COUPEZ PAS !! »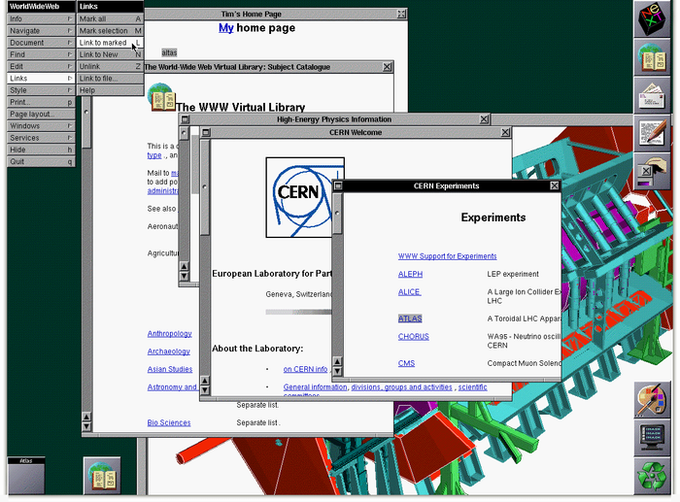
Cette page contenait des liens vers des informations sur le projet WWW lui-même, y compris une description de l’hypertexte, des détails techniques pour créer un serveur Web et des liens vers d’autres serveurs Web dès qu’ils devenaient disponibles.
La conception du WWW a permis un accès facile aux informations existantes et une première page Web liée à des informations utiles aux scientifiques du CERN (par exemple, l’annuaire téléphonique du CERN et les guides d’utilisation des ordinateurs centraux du CERN). Une fonction de recherche s’appuyait sur des mots-clés – il n’y avait pas de moteurs de recherche dans les premières années. Le navigateur Web original de Berners-Lee fonctionnant sur les ordinateurs NeXT a montré sa vision et avait de nombreuses fonctionnalités des navigateurs Web actuels. En outre, il comprenait la possibilité de modifier des pages directement à l’intérieur du navigateur – la première capacité d’édition Web. Cette capture d’écran montre le navigateur exécuté sur un ordinateur NeXT en 1993.
Le navigateur Web original de Berners-Lee fonctionnant sur les ordinateurs NeXT a montré sa vision et avait de nombreuses fonctionnalités des navigateurs Web actuels. En outre, il comprenait la possibilité de modifier des pages directement à l’intérieur du navigateur – la première capacité d’édition Web. Cette capture d’écran montre le navigateur exécuté sur un ordinateur NeXT en 1993.
Le Web s’étend
Seuls quelques utilisateurs avaient accès à une plate-forme informatique NeXT sur laquelle le premier navigateur fonctionnait, mais le développement a rapidement commencé sur un navigateur plus simple en «mode ligne», qui pouvait fonctionner sur n’importe quel système. Il a été écrit par Nicola Pellow lors de son stage d’étudiant au CERN. En 1991, Berners-Lee a sorti son logiciel WWW. Il comprenait le navigateur « en mode ligne », un logiciel de serveur Web et une bibliothèque pour les développeurs. En mars 1991, le logiciel a été mis à la disposition des collègues utilisant des ordinateurs du CERN. Quelques mois plus tard, en août 1991, il a annoncé le logiciel WWW sur les groupes de discussion Internet et l’intérêt pour le projet s’est répandu dans le monde entier.
En 1991, Berners-Lee a sorti son logiciel WWW. Il comprenait le navigateur « en mode ligne », un logiciel de serveur Web et une bibliothèque pour les développeurs. En mars 1991, le logiciel a été mis à la disposition des collègues utilisant des ordinateurs du CERN. Quelques mois plus tard, en août 1991, il a annoncé le logiciel WWW sur les groupes de discussion Internet et l’intérêt pour le projet s’est répandu dans le monde entier.
Se mondialiser


 Normes ouvertes
Normes ouvertes
Un point essentiel était que le Web devait rester une norme ouverte à l’usage de tous et que personne ne devrait l’enfermer dans un système propriétaire. Dans cet esprit, le CERN a soumis une proposition à la Commission de l’Union européenne dans le cadre du programme ESPRIT : « WebCore ». L’objectif du projet était de former un consortium international, en collaboration avec le Massachusetts Institute of Technology (MIT) américain. En 1994, Berners-Lee quitte le CERN pour rejoindre le MIT et fonde l’International World Wide Web Consortium (W3C). Entre-temps, alors que l’approbation du projet LHC était clairement en vue, le CERN a décidé que la poursuite du développement Web était une activité au-delà de la mission principale du laboratoire. Un nouveau partenaire européen pour le W3C était nécessaire.
 La naissance du Web
La naissance du Web
Tim Berners-Lee, un scientifique britannique, a inventé le World Wide Web (WWW) en 1989, alors qu’il travaillait au CERN. Le Web a été conçu et développé à l’origine pour répondre à la demande de partage automatisé d’informations entre les scientifiques des universités et des instituts du monde entier.
Le premier site Web du CERN – et du monde – était dédié au projet World Wide Web lui-même et était hébergé sur l’ordinateur NeXT de Berners-Lee. En 2013, le CERN a lancé un projet de restauration de ce tout premier site Internet : info.cern.ch .
Le 30 avril 1993, le CERN a mis le logiciel World Wide Web dans le domaine public. Plus tard, le CERN a rendu une version disponible avec une licence ouverte, un moyen plus sûr de maximiser sa diffusion. Ces actions ont permis au web de prospérer.
Le 30 avril 1993, le CERN a publié une déclaration qui rendait la technologie du World Wide Web disponible sans redevance, permettant au Web de prospérer
Le 30 avril 1993, le CERN a placé le logiciel World Wide Web dans le domaine public . Le CERN a rendu la prochaine version disponible avec une licence ouverte, comme un moyen plus sûr de maximiser sa diffusion. Grâce à ces actions, mettant à disposition gratuitement le logiciel nécessaire pour faire fonctionner un serveur Web, ainsi qu’un navigateur de base et une bibliothèque de code, le Web a pu prospérer.Le physicien britannique Tim Berners-Lee a inventé le Web au CERN en 1989. Le projet, que Berners-Lee a nommé « World Wide Web », a été conçu et développé à l’origine pour répondre à la demande de partage d’informations entre les physiciens des universités et des instituts du monde entier.
D’autres systèmes de recherche d’informations qui utilisaient Internet – tels que WAIS et Gopher – étaient disponibles à l’époque, mais la simplicité du Web ainsi que le fait que la technologie était libre de droits ont conduit à son adoption et à son développement rapides.
« Il n’y a pas de secteur de la société qui n’ait été transformé par l’invention, dans un laboratoire de physique, du web », déclare Rolf Heuer, directeur général du CERN. « De la recherche aux affaires et à l’éducation, le Web a remodelé notre façon de communiquer, de travailler, d’innover et de vivre. Le Web est un exemple puissant de la façon dont la recherche fondamentale profite à l’humanité.
Le premier site Web du CERN – et du monde – était dédié au projet World Wide Web lui-même et était hébergé sur l’ordinateur NeXT de Berners-Lee. Le site Web décrivait les fonctionnalités de base du Web ; comment accéder aux documents d’autres personnes et comment configurer votre propre serveur. Bien que la machine NeXT – le serveur Web d’origine – soit toujours au CERN, malheureusement, le premier site Web au monde n’est plus en ligne à son adresse d’origine.
Pour marquer l’anniversaire de la publication du document qui a rendu l’utilisation de la technologie Web gratuite pour tous, le CERN lance un projet visant à restaurer le premier site Web et à préserver les actifs numériques associés à la naissance du Web.
On April 22, 1993, the World Wide Web was made accessible to the public. PS – It’s also International Earth Day! 🌎🌍🌏 #PopCulture pic.twitter.com/MJK1dwuJue
— Barbara’s Nostalgia (@nostalgiapix25) April 22, 2023
30 avril 1993 – World Wide Web mis à la disposition du public
Communiqué du CERN : « Le 30 avril 1993, le CERN a publié une déclaration qui rendait la technologie du World Wide Web (« W3 », ou simplement « le Web ») disponible en franchise de droits. En mettant gratuitement à disposition le logiciel nécessaire pour faire fonctionner un serveur Web, ainsi qu’un navigateur de base et une bibliothèque de code, le Web a pu prospérer….
« Il n’y a pas de secteur de la société qui n’ait été transformé par l’invention, dans un laboratoire de physique, du web » , déclare Rolf Heuer, directeur général du CERN. « De la recherche aux affaires et à l’éducation, le Web a remodelé notre façon de communiquer, de travailler, d’innover et de vivre. Le Web est un exemple puissant de la façon dont la recherche fondamentale profite à l’humanité.
Pour marquer l’anniversaire de la publication du document qui a rendu l’utilisation de la technologie Web gratuite pour tous, le CERN lance un projet visant à restaurer le premier site Web et à préserver les actifs numériques associés à la naissance du Web.

Logiciel World-Wide Web au CERN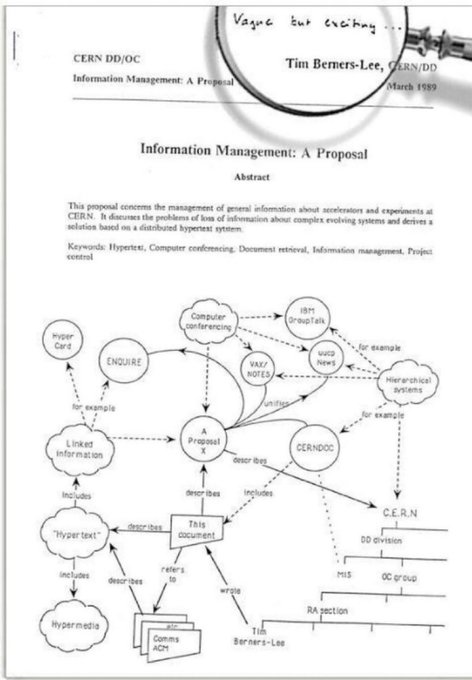
 Au cours des deux dernières années, de plus en plus d’applications World-Wide Web sont devenues disponibles auprès d’un grand nombre de fournisseurs de logiciels sur presque toutes les plates-formes connectées à Internet. Beaucoup d’entre eux sont basés sur le même modèle architectural que le logiciel du CERN mais avec des fonctionnalités supplémentaires et des performances accrues. La plupart des logiciels se caractérisent par le fait qu’ils sont librement disponibles dans le domaine public pour les établissements d’enseignement et autres organisations à but non lucratif, tandis que les sociétés commerciales doivent payer des frais pour les utiliser.
Au cours des deux dernières années, de plus en plus d’applications World-Wide Web sont devenues disponibles auprès d’un grand nombre de fournisseurs de logiciels sur presque toutes les plates-formes connectées à Internet. Beaucoup d’entre eux sont basés sur le même modèle architectural que le logiciel du CERN mais avec des fonctionnalités supplémentaires et des performances accrues. La plupart des logiciels se caractérisent par le fait qu’ils sont librement disponibles dans le domaine public pour les établissements d’enseignement et autres organisations à but non lucratif, tandis que les sociétés commerciales doivent payer des frais pour les utiliser.
Le logiciel World-Wide Web du CERN est écrit en langage C et est spécialement conçu pour être utilisé sur un large éventail de plates-formes différentes. Il a souvent été question de savoir si le code CERN ou en particulier la bibliothèque de codes communs devait être réécrit en ANSI C en utilisant la norme IEEE Std 1003.1-1990 (communément appelée POSIX.1), mais cela finira par limiter la portabilité sur de nombreuses plates-formes actuellement pris en charge . Une collaboration récemment lancée entre les fournisseurs de logiciels WWW étendra cette portabilité pour inclure également MS-DOS et MacIntosh afin que les plates-formes les plus populaires soient couvertes, des gros ordinateurs aux PC. Le document décrit le produit logiciel suivant maintenu au CERN :
(1). La bibliothèque du code commun
(2). Le navigateur de mode ligne
(3).Le serveur HTTP
(4). Le serveur proxy
La bibliothèque du code commun La bibliothèque Web mondiale de codes communs du CERN est une base de code générale qui peut être utilisée pour créer des clients et des serveurs World-Wide Web. Il contient du code pour accéder aux serveurs HTTP, FTP, Gopher, News, WAIS, Telnet et au système de fichiers local. En outre, il fournit des modules pour l’analyse, la gestion et la présentation d’objets hypertextes à l’utilisateur et un large éventail d’utilitaires de programmation génériques. La bibliothèque est la base de nombreuses applications World-Wide Web et tous les logiciels WWW du CERN sont construits dessus. Même s’il est écrit en langage C, la plupart des structures de données utilisées sont fortement orientées objet – une forme d’implémentation souvent appelée « le C++ du pauvre ». La figure suivante est un aperçu de l’architecture actuelle de la bibliothèque. La vue est spécialement destinée au côté client de la bibliothèque.
La bibliothèque Web mondiale de codes communs du CERN est une base de code générale qui peut être utilisée pour créer des clients et des serveurs World-Wide Web. Il contient du code pour accéder aux serveurs HTTP, FTP, Gopher, News, WAIS, Telnet et au système de fichiers local. En outre, il fournit des modules pour l’analyse, la gestion et la présentation d’objets hypertextes à l’utilisateur et un large éventail d’utilitaires de programmation génériques. La bibliothèque est la base de nombreuses applications World-Wide Web et tous les logiciels WWW du CERN sont construits dessus. Même s’il est écrit en langage C, la plupart des structures de données utilisées sont fortement orientées objet – une forme d’implémentation souvent appelée « le C++ du pauvre ». La figure suivante est un aperçu de l’architecture actuelle de la bibliothèque. La vue est spécialement destinée au côté client de la bibliothèque. 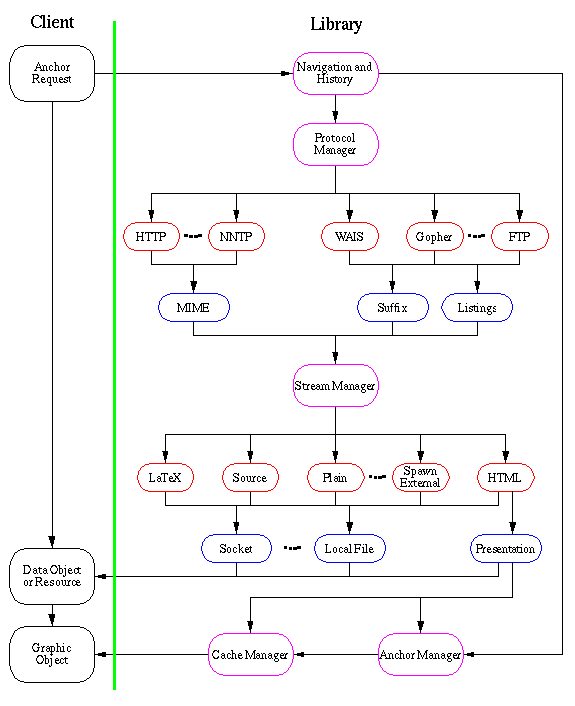 Le flux de la bibliothèque montre que toutes les communications réseau et l’analyse des objets de données sont gérées en interne. Seule la présentation à l’utilisateur est laissée au client car il s’agit d’une tâche très dépendante de la plate-forme. Les principaux éléments de la figure sont expliqués dans les sections suivantes. Une description plus spécifique de la mise en œuvre de la bibliothèque est donnée dans le guide des composants internes et du programmeur
Le flux de la bibliothèque montre que toutes les communications réseau et l’analyse des objets de données sont gérées en interne. Seule la présentation à l’utilisateur est laissée au client car il s’agit d’une tâche très dépendante de la plate-forme. Les principaux éléments de la figure sont expliqués dans les sections suivantes. Une description plus spécifique de la mise en œuvre de la bibliothèque est donnée dans le guide des composants internes et du programmeur
Objet graphique: Un objet graphique est une entité affichable gérée et maintenue par le client. Il est construit à partir des données contenues dans une réponse du serveur suite à une requête réussie initiée par le client. L’objet peut soit être construit directement à partir des données, par exemple, si l’objet de données renvoyé est un document HTML, soit il peut être généré à partir d’un convertisseur de format dans la bibliothèque. Ce dernier pourrait être la génération d’un objet HTML à partir d’un listing de répertoire FTP (ASCII 7 bits).
Les objets graphiques sont en général nécessairement codés différemment selon les systèmes de fenêtres. L’objet graphique est chargé de s’afficher, de capter les clics de souris et d’appeler l’objet de navigation afin de suivre les liens. Souvent, le terme « document » le plus courant est utilisé pour décrire l’entité logique qu’un objet graphique représente et affiche. Pour le moment, un objet graphique est créé et maintenu du côté client de la bibliothèque et du client lui-même. Cependant, il serait possible d’étendre la définition d’un objet graphique pour décrire également un objet de données transféré du serveur au client en utilisant le protocole HTTP. Le client peut alors utiliser les méta-informations fournies dans l’objet graphique pour afficher les données brutes dans la représentation souhaitée ou disponible dans le client.
Pour le moment, un objet graphique est créé et maintenu du côté client de la bibliothèque et du client lui-même. Cependant, il serait possible d’étendre la définition d’un objet graphique pour décrire également un objet de données transféré du serveur au client en utilisant le protocole HTTP. Le client peut alors utiliser les méta-informations fournies dans l’objet graphique pour afficher les données brutes dans la représentation souhaitée ou disponible dans le client.
Gestionnaire d’ancrage : Les ancres représentent des parties d’objets graphiques qui peuvent être des sources ou des destinations de liens. Il existe essentiellement deux types d’ancres : les ancres parents et les ancres enfants . Ancres parents : Ceux-ci représentent des objets graphiques entiers (documents). Chaque objet graphique a une ancre parent associée. À une ancre parente sont associées des données comprenant :
Ancres parents : Ceux-ci représentent des objets graphiques entiers (documents). Chaque objet graphique a une ancre parent associée. À une ancre parente sont associées des données comprenant :
- Le titre du document associé, s’il est connu. Cela permet d’afficher le titre du document dans les listes des nœuds précédemment visités, etc., même lorsque le document lui-même a été libéré.
- Un indicateur indiquant si le document est un index
- L’adresse du document. Lorsqu’une nouvelle ancre est créée, le code garantit que si une ancre avec cette adresse existe déjà, cette ancre est renvoyée à la place, de sorte qu’aucun doublon ne peut exister. Un problème concernant les ancres parentes est de savoir quand deux URL sont équivalentes, c’est-à-dire qu’elles pointent vers la même ressource sur le Web. Les alias d’hôte , les liens symboliques et d’autres contraintes rendent une comparaison directe impossible même si les URL sont canonisées.
- Une liste d’enfants
Ancres enfants : Ceux-ci représentent des parties de documents. L’objet graphique stocke la corrélation entre l’identité de l’ancre et la forme d’espace réelle à laquelle il est fait référence. Les ancres enfants contiennent
- Un pointeur vers le parent
- Adresse de cette ancre par rapport à l’ancre mère
La relation entre les ancres parents et les ancres enfants peut être illustrée comme suit :
Une ancre peut être la source de zéro, un ou plusieurs liens . Il a un lien « principal » pour le cas (courant) dans lequel il est la source d’un lien. Lors de la publication d’un objet de données sur, par exemple, un groupe de discussion NNTP ou en utilisant la méthode POST dans le protocole HTTP , il est courant d’avoir plus d’un destinataire pour l’objet de données à publier. La liste des destinataires sont tous dans la « liste de liens » de l’ancre, ceci est expliqué dans une section ultérieure sur Put and Post
Une ancre peut être la destination de zéro, un ou plusieurs liens. Le module d’ancrage stocke tous les liens connus par le programme, et gère donc en fait une copie d’une petite partie du Web.
Gestionnaire de cache : Il s’agit d’un module de cache local spécifiquement pour les clients WWW. Il est utilisé pour enregistrer les objets de données une fois qu’ils ont été téléchargés à partir d’Internet. Le serveur proxy du CERN possède son propre gestionnaire de cache pour gérer un cache à grande échelle qui peut servir des centaines de clients avec des documents une fois qu’ils ont été reçus de l’hôte distant. Le cache client est fait pour les clients n’utilisant pas de cache proxy ou ayant une liaison très lente mais un gros stockage temporaire local.
Navigation et historique : Ce module conserve la trace de la partie du Web que l’utilisateur a visitée au cours de la session World-Wide Web. Lorsqu’une requête est transmise du client à la bibliothèque, ce module recherche la liste des ressources précédemment demandées gérées par le gestionnaire d’ancrage. S’il a déjà été accédé, il vérifie d’abord si l’objet graphique est toujours en mémoire sur la machine cliente ou, dans le cas contraire, il demande au gestionnaire de cache si l’objet est stocké dans un stockage temporaire (système de fichiers local) côté client. La différence entre un objet de données en cache et en mémoire est que la version mémoire est un objet graphique alors que la version cache est une ressource qui doit être chargée en mémoire et transmise pour être transformée en objet graphique.
Gestionnaire de protocole : Le gestionnaire de protocole est invoqué par le client pour accéder à un document. Chaque module de protocole est chargé d’extraire des informations d’un fichier local ou d’un serveur distant à l’aide d’un protocole particulier. Selon le protocole, le module de protocole construit lui-même un objet graphique (par exemple un hypertexte) ou il transmet un descripteur de socket au gestionnaire de format pour qu’il soit analysé par l’un des modules d’analyseur. Comme mentionné dans la section Objet graphique, il peut également effectuer une conversion des données brutes renvoyées par le serveur distant en, par exemple, un objet HTML. Gestionnaire de flux : Les flux sont des objets unidirectionnels qui acceptent d’y écrire des caractères, des chaînes et des blocs de données. Le gestionnaire de flux gère une représentation générique d’une classe de flux afin que l’interface soit toujours la même pour tous les types de flux d’entrée et de sortie différents vers le gestionnaire.
Gestionnaire de flux : Les flux sont des objets unidirectionnels qui acceptent d’y écrire des caractères, des chaînes et des blocs de données. Le gestionnaire de flux gère une représentation générique d’une classe de flux afin que l’interface soit toujours la même pour tous les types de flux d’entrée et de sortie différents vers le gestionnaire.
Les flux peuvent être considérés comme des fichiers ouverts en écriture. L’architecture basée sur les flux permet au logiciel d’être piloté par les événements dans le sens où lorsque l’entrée arrive, elle est placée dans un flux, et toutes les actions nécessaires en découlent ensuite. Le flux peut être mis en cascade de sorte qu’un flux écrit dans un autre flux après avoir effectué un traitement sur les données. Un flux de sortie est souvent appelé flux « cible » ou « récepteur ».
Flux structurés : Un flux structuré est une sous-classe d’un flux , mais au lieu d’accepter uniquement des données, il accepte également des événements SGML tels que des éléments de début et de fin. Un flux structuré représente donc un document structuré. Un flux structuré peut être considéré comme la sortie d’un analyseur SGML. Il est plus efficace pour les modules qui génèrent des objets hypertextes de sortir un flux structuré que de sortir du SGML qui est ensuite analysé. Les éléments et les entités du flux sont référencés par des nombres plutôt que par des chaînes.  La DTD contient le mappage entre les noms d’éléments et les numéros, de sorte que chaque flux structuré lors de sa création est associé à la DTD qu’il utilise. Toute instance d’un flux structuré a une DTD associée qui donne les règles et les noms d’éléments et d’entités pour les événements sur le flux structuré. La seule DTD qui se trouve actuellement dans la bibliothèque est une version étendue d’une DTD HTML version 1.0.
La DTD contient le mappage entre les noms d’éléments et les numéros, de sorte que chaque flux structuré lors de sa création est associé à la DTD qu’il utilise. Toute instance d’un flux structuré a une DTD associée qui donne les règles et les noms d’éléments et d’entités pour les événements sur le flux structuré. La seule DTD qui se trouve actuellement dans la bibliothèque est une version étendue d’une DTD HTML version 1.0.
L’analyseur SGML utilise une DTD pour générer un flux structuré à partir d’un flux SGML. Un éditeur hypertexte sortira dans un flux structuré lors de la rédaction d’un document. De nombreux modules de protocole sortent vers un flux de structures lors de la génération de leurs structures de données.
Conversion de format et piles de flux : Souvent, on souhaite effectuer une conversion de format entre le point d’entrée et le point de sortie du flux. Comme illustré sur la figure de la bibliothèque, le gestionnaire de flux est le nœud entre le format d’entrée donné par les modules de protocole et le format de sortie souhaité spécifié par le client. Cependant, il est souvent souhaitable d’effectuer plusieurs conversions de données sur un objet de données. Par conséquent, le gestionnaire de flux est conçu comme une pile de flux où plusieurs flux peuvent être mis en cascade, chacun effectuant une partie de la conversion totale des données.
Le navigateur de mode ligne : Le navigateur en mode ligne du CERN est un navigateur Web basé sur des caractères. Il est développé pour être utilisé sur des terminaux muets et comme outil de test pour la bibliothèque commune de codes du CERN . Il peut être exécuté en mode interactif, en mode non interactif, en tant que client proxy et un ensemble d’autres modes d’exécution qui sont tous expliqués dans Options de ligne de commande . Même s’il n’est pas souvent utilisé comme navigateur Web, la possibilité de l’exécuter en arrière-plan ou à partir d’un traitement par lots en fait un outil utile. En outre, il offre une variété de possibilités pour la conversion de format de données, le filtrage, etc.
Le moyen le plus simple de se faire une idée de ce qu’est le navigateur en mode ligne est en fait d’essayer directement depuis le serveur d’informations du CERN . Aucun identifiant ou mot de passe n’est nécessaire.
Le serveur HTTP : CERN httpd est un serveur hypertexte générique qui peut être utilisé comme un serveur HTTP normal. Le port alloué pour les connexions HTTP est le port TCP 80, mais le serveur peut être mis en place pour écouter sur n’importe quel autre port TCP (au-dessus de 1024 s’il ne s’exécute pas en tant que root). Le serveur du CERN comprend des fonctionnalités telles que l’authentification d’accès , les images cliquables , etc.
Le serveur proxy : Le serveur du CERN a également la possibilité de fonctionner en tant que serveur proxy . Un proxy est un serveur HTTP spécial qui s’exécute généralement sur une machine pare-feu. Le proxy attend une demande de l’intérieur du pare-feu, transmet la demande au serveur distant à l’extérieur du pare-feu, lit la réponse puis la renvoie au client. Kevin Altis , Ari Luotonen et Lou Montulli ont été les principaux concepteurs de la norme de procuration actuelle, comme illustré dans la figure suivante : 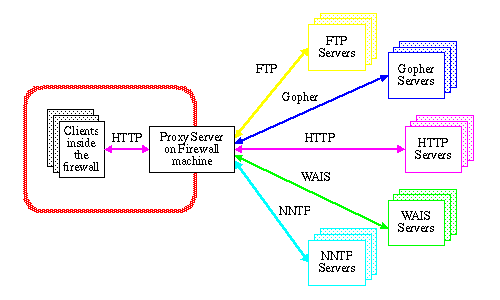 Comme le montre la figure, toutes les communications entre le client à l’intérieur du pare-feu et le serveur proxy se font via HTTP. Cela rend l’application client beaucoup plus efficace car elle peut se concentrer sur l’interface utilisateur et non sur l’interface Internet, y compris les clients de protocole de présentation, etc.
Comme le montre la figure, toutes les communications entre le client à l’intérieur du pare-feu et le serveur proxy se font via HTTP. Cela rend l’application client beaucoup plus efficace car elle peut se concentrer sur l’interface utilisateur et non sur l’interface Internet, y compris les clients de protocole de présentation, etc.
Le serveur du CERN disposait depuis longtemps de fonctionnalités de passerelle fournies par Tim Berners-Lee , mais celles-ci ont récemment été étendues pour prendre en charge toutes les méthodes du protocole HTTP utilisées par les clients WWW . Les clients ne perdent aucune fonctionnalité en passant par un proxy, à l’exception du traitement spécial qu’ils peuvent avoir effectué pour les protocoles Web non natifs tels que Gopher et FTP.
https://home.cern/science/computing/birth-web/short-history-web
https://home.cern/news/news/computing/twenty-years-free-open-web
https://blog.thegovlab.org/post/april-30-1993-world-wide-web-made-availble-to-the-public