 Qui était Konrad Bloch ?
Qui était Konrad Bloch ? 
 Une autre expérience influente a été d’assister aux sessions de la Münchener Chemische Gesellschaft et d’entendre les grands chimistes organiques de l’époque, Adolph Windaus, Heinrich Wieland et Rudolf Willstätter rapportent leurs recherches sur les stéroïdes, les porphyrines et les enzymes. Pour des raisons raciales, ses études à Munich se sont terminées en 1934 après avoir obtenu le diplôme d’ingénieur diplômé en chimie. En quittant l’Allemagne, Bloch a eu la chance de trouver un poste temporaire au Schweizerische Forschungs institut de Davos, en Suisse. Sa mission là-bas était d’étudier les phospholipides des bacilles tuberculeux, sa première exposition à la recherche biochimique.
Une autre expérience influente a été d’assister aux sessions de la Münchener Chemische Gesellschaft et d’entendre les grands chimistes organiques de l’époque, Adolph Windaus, Heinrich Wieland et Rudolf Willstätter rapportent leurs recherches sur les stéroïdes, les porphyrines et les enzymes. Pour des raisons raciales, ses études à Munich se sont terminées en 1934 après avoir obtenu le diplôme d’ingénieur diplômé en chimie. En quittant l’Allemagne, Bloch a eu la chance de trouver un poste temporaire au Schweizerische Forschungs institut de Davos, en Suisse. Sa mission là-bas était d’étudier les phospholipides des bacilles tuberculeux, sa première exposition à la recherche biochimique. 
En 1946, Bloch a déménagé à l’Université de Chicago en tant que professeur adjoint de biochimie. Les nominations au poste de professeur agrégé et de professeur ont suivi en 1948 et 1950, respectivement. A Chicago, dans le département de biochimie dirigé par EA Evans Jr., le climat intellectuel était stimulant et les conditions idéales pour le développement de jeunes chercheurs. Les travaux sur le cholestérol, la biosynthèse ont été poursuivis et ont bien progressé avec l’aide d’étudiants capables et enthousiastes. Au cours des années passées à Chicago, Bloch a également étudié (avec J. Snoke) la synthèse enzymatique du tripeptide glutathion.
 En tant que boursier Guggenheim en 1953, il a passé une année très enrichissante à l’Organisch-Chemisches Institut, Eidgenössische Technische Hochschule à Zurich avec L. Ruzicka, V. Preloget leurs collègues. Les considérations biogénétiques sur les relations terpènes-stérols développées par le Suisse à cette époque ont fourni une riche inspiration pour les travaux expérimentaux dans son propre laboratoire après son retour aux États-Unis.
En tant que boursier Guggenheim en 1953, il a passé une année très enrichissante à l’Organisch-Chemisches Institut, Eidgenössische Technische Hochschule à Zurich avec L. Ruzicka, V. Preloget leurs collègues. Les considérations biogénétiques sur les relations terpènes-stérols développées par le Suisse à cette époque ont fourni une riche inspiration pour les travaux expérimentaux dans son propre laboratoire après son retour aux États-Unis. 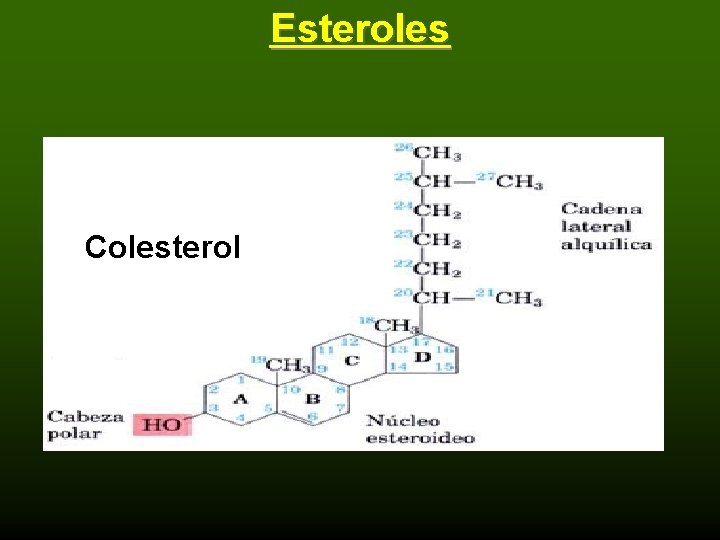 En 1954, Bloch a été nommé professeur Higgins de biochimie au département de chimie de l’Université de Harvard, et en 1968, il est devenu président du département. Outre la poursuite des recherches sur divers aspects de la biogenèse des terpènes et des stérols, il s’est intéressé à la formation enzymatique des acides gras insaturés et plus récemment à divers aspects de l’évolution biochimique.
En 1954, Bloch a été nommé professeur Higgins de biochimie au département de chimie de l’Université de Harvard, et en 1968, il est devenu président du département. Outre la poursuite des recherches sur divers aspects de la biogenèse des terpènes et des stérols, il s’est intéressé à la formation enzymatique des acides gras insaturés et plus récemment à divers aspects de l’évolution biochimique.

La synthèse enzymatique d’ADN entre dans une nouvelle phase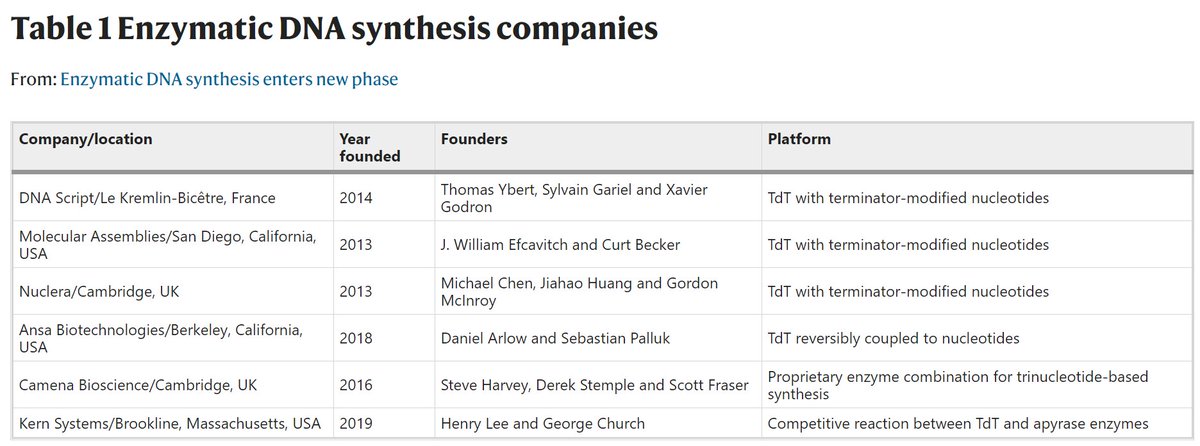
 En juin 2020, la société d’ingénierie des protéines Codexis a annoncé une collaboration dans le cadre de laquelle elle achetait pour 1 million de dollars d’actions de Molecular Assemblies afin d’accélérer les travaux de cette dernière société sur la synthèse d’ADN par voie enzymatique. Cela fait partie d’une tranche d’investissement en plein essor dans le secteur, alors que plusieurs startups ont commencé à démontrer la faisabilité de la synthèse enzymatique en tant qu’alternative rapide, précise et efficace à la synthèse chimique conventionnelle de l’ADN.
En juin 2020, la société d’ingénierie des protéines Codexis a annoncé une collaboration dans le cadre de laquelle elle achetait pour 1 million de dollars d’actions de Molecular Assemblies afin d’accélérer les travaux de cette dernière société sur la synthèse d’ADN par voie enzymatique. Cela fait partie d’une tranche d’investissement en plein essor dans le secteur, alors que plusieurs startups ont commencé à démontrer la faisabilité de la synthèse enzymatique en tant qu’alternative rapide, précise et efficace à la synthèse chimique conventionnelle de l’ADN.  Juillet a vu 50 millions de dollars supplémentaires dans un financement de série B destiné à DNA Script, et Ansa Biotechnology a récemment annoncé une injection de 7,9 millions de dollars d’un groupe d’investisseurs dirigé par Horizons Ventures. « Le domaine a vraiment pris son envol », déclare le cofondateur de Molecular Assemblies et CSO J. William Efcavitch, « Il est venu sur le devant de la scène ces dernières années, et c’est quelque chose sur lequel tout le monde veut en savoir plus. »
Juillet a vu 50 millions de dollars supplémentaires dans un financement de série B destiné à DNA Script, et Ansa Biotechnology a récemment annoncé une injection de 7,9 millions de dollars d’un groupe d’investisseurs dirigé par Horizons Ventures. « Le domaine a vraiment pris son envol », déclare le cofondateur de Molecular Assemblies et CSO J. William Efcavitch, « Il est venu sur le devant de la scène ces dernières années, et c’est quelque chose sur lequel tout le monde veut en savoir plus. » Aujourd’hui, chaque brin d’ADN fabriqué à l’extérieur d’une cellule est produit via une technique connue sous le nom de synthèse de phosphoramidite. Ce processus, développé par Marvin Caruthers et ses collègues de l’Université du Colorado en 1981, implique plusieurs cycles d’assemblage par étapes de nucléotides chimiquement modifiés. Chaque nouvelle base ajoutée au brin d’ADN naissant est bloquée à son extrémité 5′ par un « groupe protecteur » qui empêche l’ajout de plus de nucléotides ; ce groupe est ensuite retiré en prélude au tour suivant. Près de 40 ans plus tard, la synthèse des phosphoramidites est toujours le cheval de bataille de la synthèse d’ADN dans la recherche fondamentale et appliquée, avec une myriade de fournisseurs comme Twist Biosciences, GenScript et Integrated DNA Technologies fournissant des séquences sur mesure aux laboratoires du monde entier.
Aujourd’hui, chaque brin d’ADN fabriqué à l’extérieur d’une cellule est produit via une technique connue sous le nom de synthèse de phosphoramidite. Ce processus, développé par Marvin Caruthers et ses collègues de l’Université du Colorado en 1981, implique plusieurs cycles d’assemblage par étapes de nucléotides chimiquement modifiés. Chaque nouvelle base ajoutée au brin d’ADN naissant est bloquée à son extrémité 5′ par un « groupe protecteur » qui empêche l’ajout de plus de nucléotides ; ce groupe est ensuite retiré en prélude au tour suivant. Près de 40 ans plus tard, la synthèse des phosphoramidites est toujours le cheval de bataille de la synthèse d’ADN dans la recherche fondamentale et appliquée, avec une myriade de fournisseurs comme Twist Biosciences, GenScript et Integrated DNA Technologies fournissant des séquences sur mesure aux laboratoires du monde entier. Mais ses limites sont également devenues claires. Au début, la biologie moléculaire reposait principalement sur de courtes séquences d’ADN, telles que des amorces de PCR ou des sondes pour des applications de détection moléculaire. Maintenant, les chercheurs visent des cibles beaucoup plus grandes, utilisant l’ADN synthétique comme élément de base pour assembler des gènes entiers et même des génomes synthétiques.
Mais ses limites sont également devenues claires. Au début, la biologie moléculaire reposait principalement sur de courtes séquences d’ADN, telles que des amorces de PCR ou des sondes pour des applications de détection moléculaire. Maintenant, les chercheurs visent des cibles beaucoup plus grandes, utilisant l’ADN synthétique comme élément de base pour assembler des gènes entiers et même des génomes synthétiques.  Mais des séquences aussi longues sont hors de portée du procédé phosphoramidite, où l’efficacité de la synthèse directe chute régulièrement au-delà de ~200-mers. « Une fois que vous avez atteint 120 bases, vous n’avez probablement qu’environ 50 % de rendement de produit », déclare Jiahao Huang, cofondateur de la société de synthèse enzymatique Nuclera. Cela signifie que des assemblages à plus grande échelle doivent être progressivement construits par étapes à partir de brins plus petits.
Mais des séquences aussi longues sont hors de portée du procédé phosphoramidite, où l’efficacité de la synthèse directe chute régulièrement au-delà de ~200-mers. « Une fois que vous avez atteint 120 bases, vous n’avez probablement qu’environ 50 % de rendement de produit », déclare Jiahao Huang, cofondateur de la société de synthèse enzymatique Nuclera. Cela signifie que des assemblages à plus grande échelle doivent être progressivement construits par étapes à partir de brins plus petits. Il n’est donc pas surprenant que de nombreux entrepreneurs dans le domaine de la synthèse enzymatique viennent directement du monde de la biologie synthétique, où ils ont rencontré de première main la frustration de la construction de gènes. Par exemple, le cofondateur et COO de DNA Script, Sylvain Gariel, a précédemment travaillé sur l’ingénierie des microbes pour fabriquer des biocarburants. « Nous avons passé des années à construire des constructions et des voies d’ADN [avec la synthèse chimique], et c’était un travail très frustrant et douloureux », explique Gariel. « Vous commencez à penser, ‘Pourquoi est-ce que je gaspille ma jeunesse à faire ce truc ?' ». De plus, le flux de travail de fabrication, de traitement et de purification des oligonucléotides demande beaucoup de main-d’œuvre et reste donc largement le domaine des prestataires de services, ce qui retarde tout projet nécessitant de l’ADN synthétique. Cela implique également l’utilisation de produits chimiques répertoriés comme dangereux par l’Agence américaine de protection de l’environnement.
Il n’est donc pas surprenant que de nombreux entrepreneurs dans le domaine de la synthèse enzymatique viennent directement du monde de la biologie synthétique, où ils ont rencontré de première main la frustration de la construction de gènes. Par exemple, le cofondateur et COO de DNA Script, Sylvain Gariel, a précédemment travaillé sur l’ingénierie des microbes pour fabriquer des biocarburants. « Nous avons passé des années à construire des constructions et des voies d’ADN [avec la synthèse chimique], et c’était un travail très frustrant et douloureux », explique Gariel. « Vous commencez à penser, ‘Pourquoi est-ce que je gaspille ma jeunesse à faire ce truc ?' ». De plus, le flux de travail de fabrication, de traitement et de purification des oligonucléotides demande beaucoup de main-d’œuvre et reste donc largement le domaine des prestataires de services, ce qui retarde tout projet nécessitant de l’ADN synthétique. Cela implique également l’utilisation de produits chimiques répertoriés comme dangereux par l’Agence américaine de protection de l’environnement.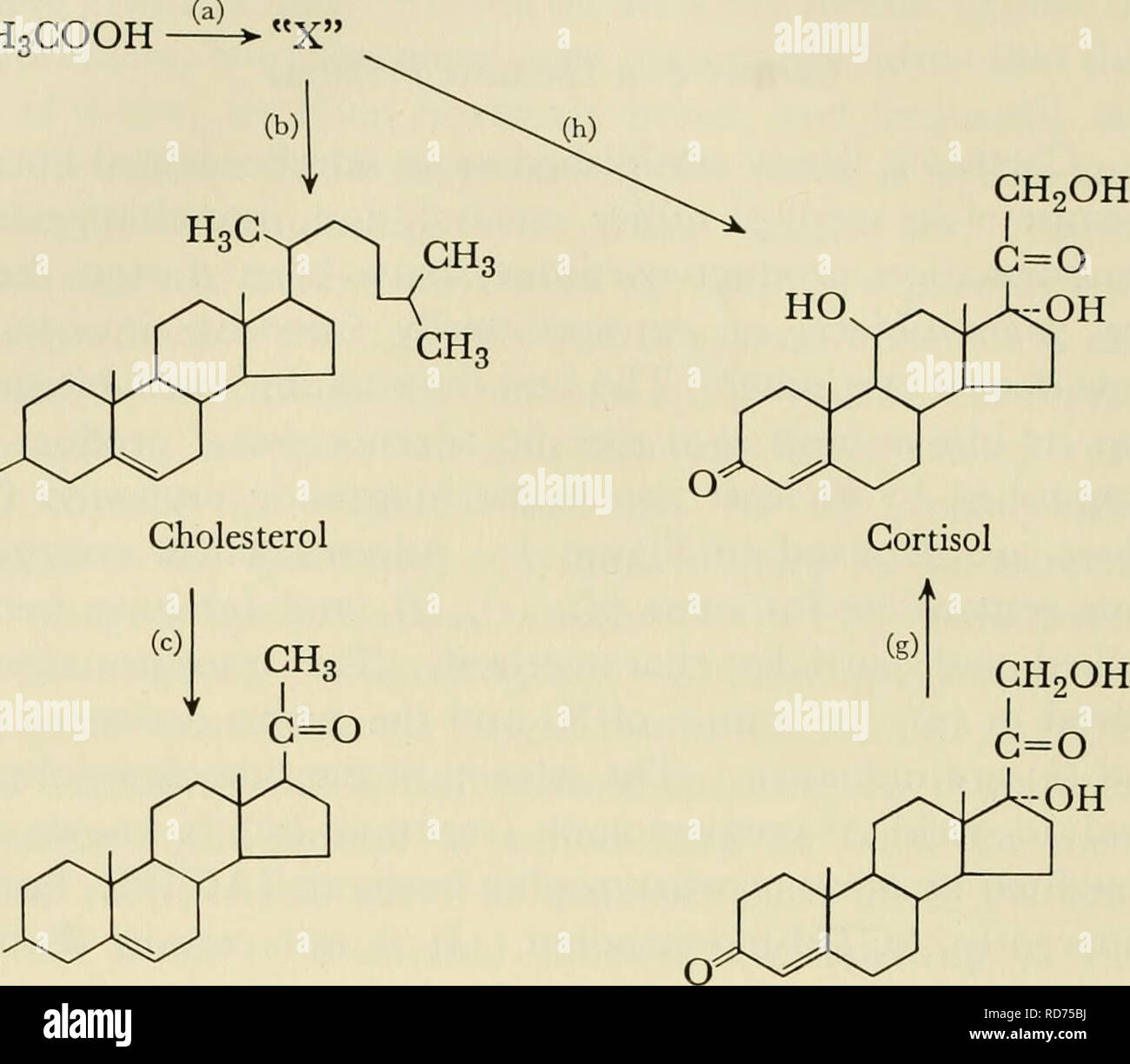 Nous avons passé des années à construire des constructions et des voies d’ADN [avec la synthèse chimique], et c’était un travail très frustrant et douloureux », explique Gariel. « Vous commencez à penser, ‘Pourquoi est-ce que je gaspille ma jeunesse à faire ce truc ?’
Nous avons passé des années à construire des constructions et des voies d’ADN [avec la synthèse chimique], et c’était un travail très frustrant et douloureux », explique Gariel. « Vous commencez à penser, ‘Pourquoi est-ce que je gaspille ma jeunesse à faire ce truc ?’
Pour remplacer le processus de phosphoramidite, les biologistes moléculaires devaient identifier une enzyme capable de synthétiser des brins d’ADN de manière indépendante de la matrice, et la plupart hébergée sur la désoxynucléotidyl transférase terminale (TdT). Dans la nature, la TdT est l’enzyme responsable de l’introduction de nucléotides supplémentaires dans les séquences de gènes codant pour les séquences des récepteurs des cellules T et B afin d’élargir la diversité des épitopes reconnus par ces cellules. Les chercheurs ont reconnu le potentiel théorique de cette enzyme comme outil de synthèse contrôlée de l’ADN depuis le début des années 1960, bien que le mécanisme et la fonction de l’enzyme soient restés mal compris pendant plusieurs décennies. Entre 2013 et 2014, la soif d’alternatives à la synthèse d’ADN a suscité un regain d’intérêt pour la TdT, et trois sociétés proposant une synthèse d’ADN basée sur la TdT – Molecular Assemblies, DNA Script et Nuclera – ont été fondées en succession rapide. Leurs stratégies sont similaires : la TdT permet l’ajout progressif de nucléotides modifiés pour incorporer un groupe « terminateur » interrompant la synthèse qui peut être éliminé par traitement chimique. Cela peut cependant être délicat, car l’enzyme TdT est pointilleuse quant aux modifications qu’elle accepte et peut nécessiter une ingénierie potentiellement étendue dans certains cas. « Nous avons choisi notre terminateur parce qu’il était petit du point de vue de la chimie stérique », explique Gariel. « Nous avons eu de la chance parce que nous avons pris la décision tôt sur la base de données limitées, mais cela s’est avéré un succès. »
Entre 2013 et 2014, la soif d’alternatives à la synthèse d’ADN a suscité un regain d’intérêt pour la TdT, et trois sociétés proposant une synthèse d’ADN basée sur la TdT – Molecular Assemblies, DNA Script et Nuclera – ont été fondées en succession rapide. Leurs stratégies sont similaires : la TdT permet l’ajout progressif de nucléotides modifiés pour incorporer un groupe « terminateur » interrompant la synthèse qui peut être éliminé par traitement chimique. Cela peut cependant être délicat, car l’enzyme TdT est pointilleuse quant aux modifications qu’elle accepte et peut nécessiter une ingénierie potentiellement étendue dans certains cas. « Nous avons choisi notre terminateur parce qu’il était petit du point de vue de la chimie stérique », explique Gariel. « Nous avons eu de la chance parce que nous avons pris la décision tôt sur la base de données limitées, mais cela s’est avéré un succès. » Ansa Biotechnologies, fondée en 2018, a adopté une approche différente, s’appuyant sur les recherches menées par les cofondateurs Dan Arlow et Sebastian Palluk alors que les deux étaient post doctorants dans le laboratoire de Jay Keasling au Joint BioEnergy Institute à Emeryville, en Californie. Ils ont reconnu la difficulté d’amener TdT à accepter des nucléotides modifiés, ils ont donc plutôt modifié l’enzyme elle-même- attacher chaque molécule de TdT à une molécule de désoxyribonucléoside triphosphate individuelle avec un lieur réversible. « Lorsque vous exposez l’extrémité 3 ‘du brin naissant à ce conjugué, il ajoute le nucléotide, puis toute l’enzyme reste attachée à l’extrémité 3′ », explique Arlow. « Cela empêche d’autres molécules conjuguées d’ajouter une deuxième base. » Cette stratégie nécessite plus d’enzymes, mais Arlow note qu’elle reste rentable car elle élimine le besoin de concentrations élevées de nucléotides modifiés coûteux.
Ansa Biotechnologies, fondée en 2018, a adopté une approche différente, s’appuyant sur les recherches menées par les cofondateurs Dan Arlow et Sebastian Palluk alors que les deux étaient post doctorants dans le laboratoire de Jay Keasling au Joint BioEnergy Institute à Emeryville, en Californie. Ils ont reconnu la difficulté d’amener TdT à accepter des nucléotides modifiés, ils ont donc plutôt modifié l’enzyme elle-même- attacher chaque molécule de TdT à une molécule de désoxyribonucléoside triphosphate individuelle avec un lieur réversible. « Lorsque vous exposez l’extrémité 3 ‘du brin naissant à ce conjugué, il ajoute le nucléotide, puis toute l’enzyme reste attachée à l’extrémité 3′ », explique Arlow. « Cela empêche d’autres molécules conjuguées d’ajouter une deuxième base. » Cette stratégie nécessite plus d’enzymes, mais Arlow note qu’elle reste rentable car elle élimine le besoin de concentrations élevées de nucléotides modifiés coûteux. Cependant, la modification chimique n’est pas strictement essentielle pour la synthèse à base de TdT. Henry Lee a conçu une stratégie sans modification avec ses collègues alors qu’il travaillait comme post-doctorant dans le laboratoire de George Church à l’Université de Harvard. L’approche met essentiellement en scène une compétition entre deux enzymes : le TdT qui ajoute des nucléotides au brin d’ADN et une enzyme apyrase qui inactive chimiquement les nucléotides restants afin qu’ils ne puissent plus être ajoutés par le TdT. Ce n’est pas aussi précis que les stratégies basées sur le terminateur, ce qui le rend moins idéal pour les applications de biologie synthétique qui nécessitent une construction extrêmement précise d’une séquence souhaitée, mais représente une bonne solution de stockage d’ADN. « Vous obtenez un ajout net, avec une certaine distribution du nombre de bases ajoutées », explique Lee. Il considère cette approche comme un bon match pour les schémas de stockage de données basés sur l’ADN, qui reposent fortement sur des mécanismes de redondance et de correction d’erreurs, et cette application est au centre de sa startup, Kern Systems.
Cependant, la modification chimique n’est pas strictement essentielle pour la synthèse à base de TdT. Henry Lee a conçu une stratégie sans modification avec ses collègues alors qu’il travaillait comme post-doctorant dans le laboratoire de George Church à l’Université de Harvard. L’approche met essentiellement en scène une compétition entre deux enzymes : le TdT qui ajoute des nucléotides au brin d’ADN et une enzyme apyrase qui inactive chimiquement les nucléotides restants afin qu’ils ne puissent plus être ajoutés par le TdT. Ce n’est pas aussi précis que les stratégies basées sur le terminateur, ce qui le rend moins idéal pour les applications de biologie synthétique qui nécessitent une construction extrêmement précise d’une séquence souhaitée, mais représente une bonne solution de stockage d’ADN. « Vous obtenez un ajout net, avec une certaine distribution du nombre de bases ajoutées », explique Lee. Il considère cette approche comme un bon match pour les schémas de stockage de données basés sur l’ADN, qui reposent fortement sur des mécanismes de redondance et de correction d’erreurs, et cette application est au centre de sa startup, Kern Systems. Mais aussi adaptée que soit la TdT à la synthèse enzymatique, plusieurs limitations importantes se sont manifestées alors que de plus en plus d’entreprises ont commencé à tester ses capacités. Par exemple, Lee note que l’enzyme présente des biais notables. « Il se soucie de la séquence terminale à laquelle il est lié, et il se soucie du nucléotide entrant », dit-il. Cela pourrait à son tour affecter la fiabilité du processus et l’efficacité avec laquelle certaines séquences peuvent être produites. Les performances peuvent également décliner si le brin en cours de synthèse commence à former des structures secondaires.
Mais aussi adaptée que soit la TdT à la synthèse enzymatique, plusieurs limitations importantes se sont manifestées alors que de plus en plus d’entreprises ont commencé à tester ses capacités. Par exemple, Lee note que l’enzyme présente des biais notables. « Il se soucie de la séquence terminale à laquelle il est lié, et il se soucie du nucléotide entrant », dit-il. Cela pourrait à son tour affecter la fiabilité du processus et l’efficacité avec laquelle certaines séquences peuvent être produites. Les performances peuvent également décliner si le brin en cours de synthèse commence à former des structures secondaires.
Une plus grande ingénierie des protéines pourrait donc être nécessaire pour améliorer les performances de l’enzyme et renforcer sa fiabilité. C’est ce besoin qui a motivé la décision de Molecular Assemblies de s’associer à Codexis. « Nous avons eu un effort d’ingénierie des protéines dans l’entreprise depuis que nous avons ouvert nos portes », explique Efcavitch, « mais Codexis a mis en place un processus d’évolution des protéines à très haut débit et une longue expérience, et c’était un simple make- décision contre achat.
La TdT n’est d’ailleurs pas la seule enzyme disponible à cet effet, même si c’est la plus connue. Par exemple, Camena Biosciences utilise une combinaison exclusive d’enzymes pour réaliser une synthèse d’ADN sans matrice à partir de blocs de construction de tri nucléotides. « Grâce à un certain nombre d’astuces, nous avons pu vraiment renforcer la précision de la synthèse », déclare le PDG et cofondateur Steve Harvey.
Après des années d’efforts, ces incursions dans la synthèse enzymatique franchissent aujourd’hui des étapes importantes en termes de performances. DNA Script a réussi à atteindre une efficacité de couplage allant jusqu’à 99,7 % avec son processus enzymatique – une mesure de la proportion de brins qui intègrent avec succès le nucléotide souhaité à chaque étape. Cela dépasse l’efficacité estimée de 99,2 à 99,3% de la chimie des phosphoramidites, explique Gariel, et sa société a signalé la synthèse réussie d’une séquence de 280 bases en février. Camena opère dans une gamme similaire avec sa technologie, qui peut désormais produire en routine du 300-mersavec une efficacité de couplage supérieure à 99,9 % selon Harvey. Mais les séquences plus longues restent difficiles, et pour l’instant, de nombreuses sociétés de synthèse enzymatique ont donné la priorité à l’amélioration de la fiabilité et de la vitesse, en s’appuyant sur des processus d’assemblage de niveau supérieur plutôt que de repousser les limites de longueur plus loin.
Avec au moins une demi-douzaine d’entreprises désormais actives dans l’espace, divers modèles commerciaux ont émergé. Nuclera et DNA Script travaillent tous deux sur des imprimantes à ADN de paillasse. DNA Script est le plus proche de la commercialisation, ayant développé un prototype de son instrument de table Syntax. La syntaxe a à peu près la taille d’un séquenceur Illumina HiSeq et devrait entrer en test bêta avant la fin de 2020. « Nous avons conçu les premières cartouches pour pouvoir fabriquer une plaque à 96 puits de 60-mers en six à sept heures », dit Gariel, notant que les oligos résultants sont également purifiés et soumis à un contrôle de qualité dans l’instrument, permettant une utilisation immédiate. Huang rapporte que l’instrument de Nuclera est maintenant dans les dernières étapes de développement et pourrait être prêt pour une démonstration au début de 2021 et un lancement au début de 2022.
Ansa et Camena cherchent plutôt à agir en tant que fournisseurs de services centralisés. « De cette façon, nous pouvons QC [contrôle qualité] tout ce qui sort et vérifier tous les gènes, de sorte que l’utilisateur n’a pas à faire de séquençage supplémentaire ou même de clonage », explique Arlow, ajoutant que cela permettra également à l’entreprise maintenir une certaine surveillance du point de vue de la biosécurité. Et pour Molecular Assemblies, l’objectif est de développer des technologies habilitantes qui pourraient être concédées sous licence par d’autres sociétés, y compris les fournisseurs d’ADN synthétique existants. Le PDG Michael Kamdar envisage leur technologie comme « l’encre de toutes les imprimantes ».
Quelques entreprises fabriquent déjà de l’ADN généré par voie enzymatique pour leurs clients, bien que sur une base limitée. DNA Script envoie des séquences d’ADN que les utilisateurs doivent tester sur demande – « bien sûr, nous avons une longue file d’attente », ajoute Gariel – et Harvey note que Camena produit des oligos pour un test COVID-19 en cours de développement. Mais plus généralement, ces séquences courtes ne sont qu’un tremplin pour pouvoir générer les séquences longues qui sont actuellement hors de portée de la synthèse chimique. «Nous essayons de fabriquer des milliers de mers et de les transformer en gènes», explique Arlow. Au-delà de la biologie synthétique, cela pourrait également aider à accélérer la production de vaccins à base d’acide nucléique ou à générer les longs brins d’ADN nécessaires à la réécriture ciblée du génome avec CRISPR par recombinaison dirigée par homologie.
Pour le stockage de données, l’objectif est quelque peu différent. En tant que biomolécule durable et riche en données, l’ADN peut potentiellement être utilisé pour coder d’énormes quantités d’informations sous forme de réseaux denses d’oligonucléotides. Mais de telles applications nécessiteront également des progrès dans le débit synthétique et des réductions du coût par base. « Les fabricants actuels peuvent faire quelques centaines de milliers de séquences en une seule fois, mais pour que le stockage d’informations fonctionne, nous devons fonctionner avec des millions ou des milliards de séquences », déclare Lee, ajoutant que Kern Systems se concentre désormais sur des solutions d’ingénierie qui pourraient atteindre ce type de débit et de densité de séquence. L’intérêt pour cette application ne cesse de croître : DNA Script fait partie d’un consortium de recherche qui a reçu 23 millions de dollars de l’US Intelligence Advanced Research Projects Activity (IARPA) pour développer des technologies basées sur l’ADN qui peuvent réaliser un stockage de données à l’échelle de l’exaoctet. Et en août, la société de synthèse chimique d’ADN Twist Biosciences a annoncé qu’elle avait utilisé son ADN comme support de stockage de données pour des épisodes complets de la série Netflix Biohackers
Si les principes de base de la synthèse enzymatique s’avèrent dans ces applications, la capacité à puiser dans la synthèse rapide et à haut débit de longs brins d’ADN à la demande pourrait s’avérer transformatrice. Arlow est particulièrement enthousiasmé par la possibilité d’accélérer les cycles de conception-construction-test dans la recherche en biologie synthétique et d’aider ainsi le domaine à intégrer plus rapidement les premiers principes. « La biologie est la meilleure façon de réorganiser les atomes que nous avons, mais nous sommes encore assez mauvais pour l’ingénierie », dit-il. « Pour nous améliorer, je pense que nous devrons en construire beaucoup plus et apprendre ce qui fonctionne et ce qui ne fonctionne pas. »
Konrad Emil Bloch était un biochimiste germano-américain qui a partagé le prix Nobel de physiologie ou médecine en 1964 avec Feodor Lynen pour leurs découvertes concernant la synthèse naturelle du cholestérol et des acides gras. Bloch a identifié le processus chimique par lequel le corps transforme l’acide acétique en cholestérol. Il a découvert à quel point il est possible de réguler la quantité de cholestérol produite par le corps. Il a découvert que des niveaux élevés de cholestérol dans le sang provoquent des dépôts graisseux sur les parois internes des artères, ce qui peut entraîner une restriction du flux sanguin et augmenter les risques de coagulation du sang et de crise cardiaque.
https://www.nobelprize.org/prizes/medicine/1964/bloch/biographical/